计算着色器
简介
在本章中,我们将学习计算着色器。 到目前为止,所有之前的章节都涉及Vulkan管线的传统图形部分。 但与OpenGL等旧API不同,Vulkan中的计算着色器支持是强制性的。 这意味着无论您使用的是高端桌面GPU还是低功耗嵌入式设备,都可以在所有Vulkan实现上使用计算着色器。
这为图形处理器上的通用计算(GPGPU)打开了大门,无论您的应用程序运行在何处。 GPGPU意味着您可以在GPU上进行通用计算,这传统上是CPU的领域。 但随着GPU变得越来越强大和灵活,许多需要CPU通用能力的任务现在可以在GPU上实时完成。
GPU计算能力的一些应用示例包括图像处理、可见性测试、后处理、高级光照计算、动画、物理(例如粒子系统)等等。 甚至可以仅用于不需要任何图形输出的非视觉计算工作,例如数字运算或AI相关任务。 这被称为“无头计算”。
优势
在GPU上进行计算密集型计算有几个优势。 最明显的一个是减轻CPU的工作负载。 另一个是不需要在CPU的主存和GPU的内存之间移动数据。 所有数据都可以保留在GPU上,无需等待从主存进行缓慢的传输。
除此之外,GPU高度并行化,其中一些拥有数万个小型计算单元。 这使得它们比只有几个大型计算单元的CPU更适合高度并行的工作流。
Vulkan管线
重要的是要知道计算与管线的图形部分完全分离。 这可以从官方规范中的Vulkan管线框图中看出:
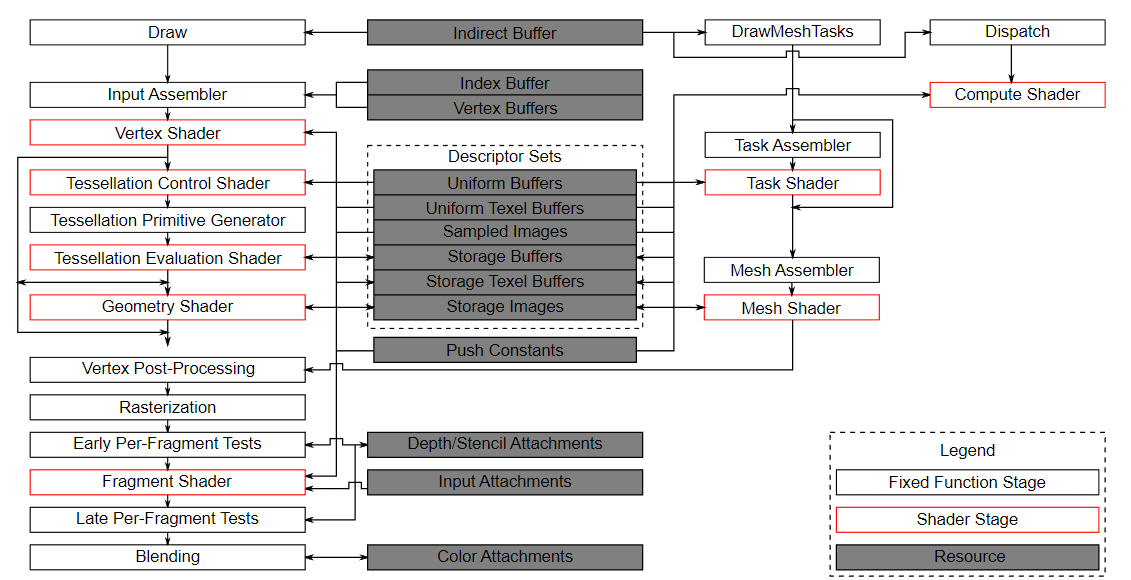
在此图中,我们可以看到左侧是管线的传统图形部分,右侧是几个不属于此图形管线的阶段,包括计算着色器(阶段)。 由于计算着色器阶段与图形管线分离,我们可以在任何需要的地方使用它。 这与例如片段着色器非常不同,后者始终应用于顶点着色器的变换输出。
图的中心还显示,例如描述符集也被计算使用,因此我们学到的关于描述符布局、描述符集和描述符的所有内容也适用于此。
示例
本章我们将实现一个易于理解的示例:基于GPU的粒子系统。 这种系统在许多游戏中使用,通常由数千个粒子组成,需要在交互式帧率下更新。 渲染这样的系统需要两个主要部分:顶点(作为顶点缓冲区传递)和基于某些方程更新它们的方法。
“经典”的基于CPU的粒子系统会将粒子数据存储在系统的主存中,然后使用CPU更新它们。 更新后,顶点需要再次传输到GPU的内存,以便它可以在下一帧中显示更新的粒子。 最直接的方法是为每一帧重新创建带有新数据的顶点缓冲区。 这是非常昂贵的。 根据您的实现,还有其他选项,例如映射GPU内存以便CPU可以写入(在桌面系统上称为“可调整大小的BAR”,或在集成GPU上称为统一内存),或者仅使用主机本地缓冲区(由于PCI-E带宽,这将是最慢的方法)。 但无论选择哪种缓冲区更新方法,您始终需要“往返”到CPU来更新粒子。
使用基于GPU的粒子系统,不再需要这种往返。 顶点仅在开始时上传到GPU,所有更新都使用计算着色器在GPU的内存中完成。 这更快的主要原因之一是GPU与其本地内存之间的带宽要高得多。 在基于CPU的场景中,您将受到主存和PCI-express带宽的限制,这通常只是GPU内存带宽的一小部分。
在具有专用计算队列的GPU上执行此操作时,可以并行更新粒子与图形管线的渲染部分。 这称为“异步计算”,是一个高级主题,本教程不涉及。
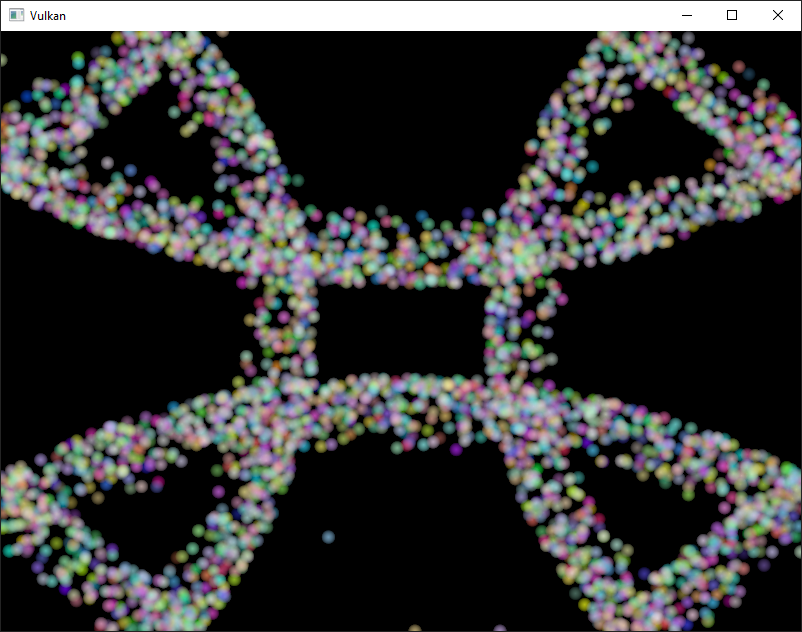
以下是本章代码的屏幕截图。 此处显示的粒子由计算着色器直接在GPU上更新,无需任何CPU交互:
数据操作
在本教程中,我们已经学习了不同的缓冲区类型,例如用于传递图元的顶点和索引缓冲区,以及用于将数据传递到着色器的统一缓冲区。 我们还使用图像进行纹理映射。 但到目前为止,我们始终使用CPU写入数据,并且仅在GPU上进行读取。
计算着色器引入的一个重要概念是能够任意从缓冲区读取*和写入*缓冲区。 为此,Vulkan提供了两种专用的存储类型。
着色器存储缓冲区对象(SSBO)
着色器存储缓冲区(SSBO)允许着色器从缓冲区读取和写入。 使用这与使用统一缓冲区对象类似。 最大的区别是您可以将其他缓冲区类型别名为SSBO,并且它们可以任意大。
回到基于GPU的粒子系统,您现在可能想知道如何处理由计算着色器更新(写入)并由顶点着色器读取(绘制)的顶点,因为这两种用法似乎需要不同的缓冲区类型。
但事实并非如此。 在Vulkan中,您可以指定缓冲区和图像的多种用途。 因此,对于粒子顶点缓冲区要在图形传递中用作顶点缓冲区并在计算传递中用作存储缓冲区,您只需创建具有这两个用途标志的缓冲区:
vk::BufferCreateInfo bufferInfo{};
...
bufferInfo.usage = vk::BufferUsageFlagBits::eVertexBuffer | vk::BufferUsageFlagBits::eStorageBuffer | vk::BufferUsageFlagBits::eTransferDst;
...
shaderStorageBuffers[i] = vk::raii::Buffer(*device, bufferInfo);使用`bufferInfo.usage`设置的两个标志`vk::BufferUsageFlagBits::eVertexBuffer`和`vk::BufferUsageFlagBits::eStorageBuffer`告诉实现我们希望将此缓冲区用于两种不同的场景:在顶点着色器中作为顶点缓冲区,以及作为存储缓冲区。
注意,我们还在此处添加了`vk::BufferUsageFlagBits::eTransferDst`标志,以便我们可以将数据从主机传输到GPU。
这至关重要,因为我们希望着色器存储缓冲区仅保留在GPU内存中(vk::MemoryPropertyFlagBits::eDeviceLocal),我们需要将数据从主机传输到此缓冲区。
以下是使用`createBuffer`辅助函数的相同代码:
vk::raii::Buffer shaderStorageBufferTemp({});
vk::raii::DeviceMemory shaderStorageBufferTempMemory({});
createBuffer(bufferSize, vk::BufferUsageFlagBits::eStorageBuffer | vk::BufferUsageFlagBits::eVertexBuffer | vk::BufferUsageFlagBits::eTransferDst, vk::MemoryPropertyFlagBits::eDeviceLocal, shaderStorageBufferTemp, shaderStorageBufferTempMemory);
copyBuffer(stagingBuffer, shaderStorageBufferTemp, bufferSize);
shaderStorageBuffers.emplace_back(std::move(shaderStorageBufferTemp));
shaderStorageBuffersMemory.emplace_back(std::move(shaderStorageBufferTempMemory));用于访问此类缓冲区的SLang着色器声明如下:
struct Particle {
float2 position;
float2 velocity;
float4 color;
};
struct ParticleSSBO {
Particle particles;
};
StructuredBuffer<ParticleSSBO> particlesIn;
RWStructuredBuffer<ParticleSSBO> particlesOut;在此示例中,我们有一个类型化的SSBO,每个粒子具有位置和速度值(参见`Particle`结构)。 SSBO包含无限数量的粒子,因为它被放入一个没有上限的`StructuredBuffer`中,并且对于`particlesIn`是一个只读缓冲区。对于`particlesOut`,我们将其放入`RWStructuredBuffer`中。 不必在SSBO中指定元素数量是相对于例如统一缓冲区的一个优势。
在计算着色器中写入此类存储缓冲区对象非常简单,类似于在C++端写入缓冲区的方式:
particlesOut[index].particles.position = particlesIn[index].particles.position + particlesIn[index].particles.velocity.xy * ubo.deltaTime;存储图像
注意:我们不会在本章中进行图像处理。 此段落旨在让读者了解计算着色器也可用于图像处理。
存储图像允许您从图像读取和写入。 典型的用例包括对纹理应用图像效果、进行后处理(这反过来非常相似)或生成mip-map。
对于图像也是如此:
vk::ImageCreateInfo imageInfo {};
...
imageInfo.usage = vk::ImageUsageFlagBits::eSampled | vk::ImageUsageFlagBits::eStorage;
...
textureImage = std::make_unique<vk::raii::SwapchainKHR>( *device, swapChainCreateInfo );使用`imageInfo.usage`设置的两个标志`vk::ImageUsageFlagBits::eSampled`和`vk::ImageUsageFlagBits::eStorage`告诉实现我们希望将此图像用于两种不同的场景:在片段着色器中作为采样图像,以及在计算着色器中作为存储图像。
存储图像的SLang着色器声明类似于例如片段着色器中使用的采样图像:
[vk::image_format("r32f")] Texture2D<float> inputImage;
[vk::image_format("r32f")] RWTexture2D<float> outputImage;这里的一些区别包括额外的属性,例如图像的格式`r32f`,使用只读的`Texture2D`和读写`RWTexture2D`指定。 最后但并非最不重要的是,我们需要使用`RWTexture2D`类型来声明存储图像。
在计算着色器中从存储图像读取和写入然后使用数组查找语法完成:
float3 pixel = inputImage[int2(gl_GlobalInvocationID.xy)].rgb;
outputImage[int2(gl_GlobalInvocationID.xy)] = pixel;计算队列族
在物理设备和队列族章节中, 我们已经了解了队列族以及如何选择图形队列族。 计算使用队列族属性标志位`vk::QueueFlagBits::eCompute`。 因此,如果我们想进行计算工作,我们需要从支持计算的队列族中获取队列。
请注意,Vulkan要求支持图形操作的实现至少有一个支持图形和计算操作的队列族,但也可能实现提供专用的计算队列。 此专用计算队列(没有图形位)暗示了异步计算队列。 但为了使本教程对初学者友好,我们将使用可以同时执行图形和计算操作的队列。 这也将使我们免于处理几种高级同步机制。
对于我们的计算示例,我们需要稍微更改设备创建代码:
std::vector<vk::QueueFamilyProperties> queueFamilyProperties = physicalDevice->getQueueFamilyProperties();
// 获取支持图形和计算的queueFamilyProperties的第一个索引
auto graphicsAndComputeQueueFamilyProperty =
std::find_if( queueFamilyProperties.begin(),
queueFamilyProperties.end(),
[]( vk::QueueFamilyProperties const & qfp ) { return (qfp.queueFlags & vk::QueueFlagBits::eGraphics && qfp.queueFlags & vk::QueueFlagBits::eCompute); } );
graphicsAndComputeIndex = static_cast<uint32_t>( std::distance( queueFamilyProperties.begin(), graphicsAndComputeQueueFamilyProperty ) );更改后的队列族索引选择代码现在将尝试找到支持图形和计算的队列族。
然后我们可以在`createLogicalDevice`中从此队列族获取计算队列:
computeQueue = std::make_unique<vk::raii::Queue>( *device, graphicsAndComputeIndex, 0 );计算着色器阶段
在图形示例中,我们使用了不同的管线阶段来加载着色器和访问描述符。 计算着色器通过使用`vk::ShaderStageFlagBits::eCompute`管线以类似的方式访问。 因此,加载计算着色器与加载顶点着色器相同,只是着色器阶段不同。 我们将在接下来的段落中详细讨论这一点。 计算还为描述符和管线引入了一个新的绑定点类型`vk::PipelineBindPoint::eCompute`,我们稍后将使用它。
加载计算着色器
在我们的应用程序中加载计算着色器与加载任何其他着色器相同。 唯一的真正区别是我们需要使用上面提到的`vk::ShaderStageFlagBits::eCompute`。
auto computeShaderCode = readFile("shaders/slang.spv");
vk::PipelineShaderStageCreateInfo computeShaderStageInfo({}, vk::ShaderStageFlagBits::eCompute, shaderModule, "compMain");
...准备着色器存储缓冲区
早些时候,我们了解到可以使用着色器存储缓冲区将任意数据传递到计算着色器。 对于此示例,我们将上传一个粒子数组到GPU,以便我们可以直接在GPU的内存中操作它。
在飞行中的帧章节中,我们讨论了每帧复制资源,以便我们可以保持CPU和GPU忙碌。 首先,我们为缓冲区对象和支持它的设备内存声明一个向量:
std::vector<vk::raii::Buffer> shaderStorageBuffers;
std::vector<vk::raii::DeviceMemory> shaderStorageBuffersMemory;在`createShaderStorageBuffers`中,我们然后清除这些向量以清理其中已创建的任何对象,这是我们的RAII实践。
shaderStorageBuffers.clear();
shaderStorageBuffersMemory.clear();有了这个设置,我们可以开始将初始粒子信息移动到GPU。 我们首先在主机端初始化一个粒子向量:
// 初始化粒子
std::default_random_engine rndEngine((unsigned)time(nullptr));
std::uniform_real_distribution<float> rndDist(0.0f, 1.0f);
// 圆形上的初始粒子位置
std::vector<Particle> particles(PARTICLE_COUNT);
for (auto& particle : particles) {
float r = 0.25f * sqrtf(rndDist(rndEngine));
float theta = rndDist(rndEngine) * 2.0f * 3.14159265358979323846f;
float x = r * cosf(theta) * HEIGHT / WIDTH;
float y = r * sinf(theta);
particle.position = glm::vec2(x, y);
particle.velocity = normalize(glm::vec2(x,y)) * 0.00025f;
particle.color = glm::vec4(rndDist(rndEngine), rndDist(rndEngine), rndDist(rndEngine), 1.0f);
}然后我们在主机的内存中创建一个暂存缓冲区来保存初始粒子属性:
vk::DeviceSize bufferSize = sizeof(Particle) * PARTICLE_COUNT;
// 创建一个用于将数据上传到GPU的暂存缓冲区
vk::raii::Buffer stagingBuffer({});
vk::raii::DeviceMemory stagingBufferMemory({});
createBuffer(bufferSize, vk::BufferUsageFlagBits::eTransferSrc, vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent, stagingBuffer, stagingBufferMemory);
void* dataStaging = stagingBufferMemory.mapMemory(0, bufferSize);
memcpy(dataStaging, particles.data(), (size_t)bufferSize);
stagingBufferMemory.unmapMemory();使用此暂存缓冲区作为源,我们然后创建每帧着色器存储缓冲区并将粒子属性从暂存缓冲区复制到每个这些缓冲区:
// 将初始粒子数据复制到所有存储缓冲区
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vk::raii::Buffer shaderStorageBufferTemp({});
vk::raii::DeviceMemory shaderStorageBufferTempMemory({});
createBuffer(bufferSize, vk::BufferUsageFlagBits::eStorageBuffer | vk::BufferUsageFlagBits::eVertexBuffer | vk::BufferUsageFlagBits::eTransferDst, vk::MemoryPropertyFlagBits::eDeviceLocal, shaderStorageBufferTemp, shaderStorageBufferTempMemory);
copyBuffer(stagingBuffer, shaderStorageBufferTemp, bufferSize);
shaderStorageBuffers.emplace_back(std::move(shaderStorageBufferTemp));
shaderStorageBuffersMemory.emplace_back(std::move(shaderStorageBufferTempMemory));
}
}描述符
为计算设置描述符与图形几乎相同。 唯一的区别是描述符需要设置`vk::ShaderStageFlagBits::eCompute`以使它们可被计算阶段访问:
std::array layoutBindings{
vk::DescriptorSetLayoutBinding(0, vk::DescriptorType::eUniformBuffer, 1, vk::ShaderStageFlagBits::eCompute, nullptr),
};
...请注意,您可以在此处组合着色器阶段,因此如果您希望描述符可从顶点和计算阶段访问,例如对于在它们之间共享参数的统一缓冲区,您可以为这两个阶段设置位:
layoutBindings[0].stageFlags = vk::ShaderStageFlagBits::eVertex | vk::ShaderStageFlagBits::eCompute;这是我们示例的描述符设置。 布局如下:
std::array layoutBindings{
vk::DescriptorSetLayoutBinding(0, vk::DescriptorType::eUniformBuffer, 1, vk::ShaderStageFlagBits::eCompute, nullptr),
vk::DescriptorSetLayoutBinding(1, vk::DescriptorType::eStorageBuffer, 1, vk::ShaderStageFlagBits::eCompute, nullptr),
vk::DescriptorSetLayoutBinding(2, vk::DescriptorType::eStorageBuffer, 1, vk::ShaderStageFlagBits::eCompute, nullptr)
};
vk::DescriptorSetLayoutCreateInfo layoutInfo({}, layoutBindings.size(), layoutBindings.data());
computeDescriptorSetLayout = std::make_unique<vk::raii::DescriptorSetLayout>( *device, layoutInfo );查看此设置,您可能想知道为什么我们有两个着色器存储缓冲区对象的布局绑定,尽管我们只会渲染一个粒子系统。 这是因为粒子位置是基于增量时间逐帧更新的。 这意味着每帧需要了解上一帧的粒子位置,因此它可以用新的增量时间更新它们并将它们写入自己的SSBO:

为此,计算着色器需要访问上一帧和当前帧的SSBO。 这是通过在我们的描述符设置中传递两者来完成的。 请参阅`storageBufferInfoLastFrame`和`storageBufferInfoCurrentFrame`:
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vk::DescriptorBufferInfo bufferInfo(uniformBuffers[i], 0, sizeof(UniformBufferObject));
vk::DescriptorBufferInfo storageBufferInfoLastFrame(shaderStorageBuffers[(i - 1) % MAX_FRAMES_IN_FLIGHT], 0, sizeof(Particle) * PARTICLE_COUNT);
vk::DescriptorBufferInfo storageBufferInfoCurrentFrame(shaderStorageBuffers[i], 0, sizeof(Particle) * PARTICLE_COUNT);
std::array descriptorWrites{
vk::WriteDescriptorSet( computeDescriptorSets[i], 0, 0, 1, vk::DescriptorType::eUniformBuffer, nullptr, &bufferInfo ),
vk::WriteDescriptorSet( computeDescriptorSets[i], 1, 0, 1, vk::DescriptorType::eStorageBuffer, nullptr, &storageBufferInfoLastFrame),
vk::WriteDescriptorSet( computeDescriptorSets[i], 2, 0, 1, vk::DescriptorType::eStorageBuffer, nullptr, &storageBufferInfoCurrentFrame),
};
device->updateDescriptorSets(descriptorWrites, {});
}请记住,我们还必须从我们的描述符池中请求SSBO的描述符类型:
std::array poolSize {
vk::DescriptorPoolSize( vk::DescriptorType::eUniformBuffer, MAX_FAMES_IN_FLIGHT),
vk::DescriptorPoolSize( vk::DescriptorType::eStorageBuffer, MAX_FAMES_IN_FLIGHT * 2)
};我们需要将`vk::DescriptorType::eStorageBuffer`类型的数量从池中请求加倍,因为我们的集合引用了上一帧和当前帧的SSBO。
计算管线
由于计算不是图形管线的一部分,我们不能使用`device→createGraphicsPipeline`。 相反,我们需要创建一个专用的计算管线`device→createComputePipeline`来运行我们的计算命令。 由于计算管线不涉及任何光栅化状态,它的状态比图形管线少得多:
vk::PipelineLayoutCreateInfo pipelineLayoutInfo({}, 1, &**computeDescriptorSetLayout);
computePipelineLayout = std::make_unique<vk::raii::PipelineLayout>( *device, pipelineLayoutInfo );设置要简单得多,因为我们只需要一个着色器阶段和一个管线布局。 管线布局的工作方式与图形管线相同:
vk::ComputePipelineCreateInfo pipelineInfo({}, computeShaderStageInfo, *computePipelineLayout);
computePipeline = std::make_unique<vk::raii::Pipeline>(device->createComputePipeline( nullptr, pipelineInfo));计算空间
在我们讨论计算着色器如何工作以及如何将计算工作负载提交到GPU之前,我们需要讨论两个重要的计算概念:工作组*和*调用。 它们定义了一个抽象的执行模型,用于描述计算工作负载如何由GPU的计算硬件在三个维度(x、y和z)上处理。
*工作组*定义了计算工作负载如何形成并由GPU的计算硬件处理。 您可以将它们视为GPU必须处理的工作项。 工作组的维度由应用程序在命令缓冲区时间使用调度命令设置。
每个工作组然后是一组*调用*的集合,这些调用执行相同的计算着色器。 调用可以并行运行,它们的维度在计算着色器中设置。 单个工作组内的调用可以访问共享内存。
此图像显示了这两个在三个维度上的关系:

工作组(由`computeCommandBuffers[currentFrame]→dispatch`定义)和调用(由计算着色器中的局部大小定义)的维度数量取决于输入数据的结构。 如果您例如处理一维数组,就像我们在本章中所做的那样,您只需要为两者指定x维度。
例如:如果我们调度一个工作组计数为[64, 1, 1],计算着色器局部大小为[32, 32, 1],我们的计算着色器将被调用64 x 32 x 32 = 65,536次。
请注意,工作组和局部大小的最大计数因实现而异,因此您应始终检查`VkPhysicalDeviceLimits`中的计算相关`maxComputeWorkGroupCount`、`maxComputeWorkGroupInvocations`和`maxComputeWorkGroupSize`限制。
计算着色器
现在我们已经了解了设置计算着色器管线所需的所有部分,是时候看看计算着色器了。 我们学到的关于使用GLSL着色器的所有内容,例如顶点和片段着色器,也适用于计算着色器。 语法相同,许多概念(如在应用程序和着色器之间传递数据)也相同。 但有一些重要的区别。
一个用于更新线性粒子数组的非常基本的计算着色器可能如下所示:
struct Particle {
float2 position;
float2 velocity;
float4 color;
};
struct UniformBuffer {
float deltaTime;
};
ConstantBuffer<UniformBuffer> ubo;
struct ParticleSSBO {
Particle particles;
};
StructuredBuffer<ParticleSSBO> particlesIn;
RWStructuredBuffer<ParticleSSBO> particlesOut;
[shader("compute")]
[numthreads(256,1,1)]
void compMain(uint3 threadId : SV_DispatchThreadID)
{
uint index = threadId.x;
particlesOut[index].particles.position = particlesIn[index].particles.position + particlesIn[index].particles.velocity.xy * ubo.deltaTime;
particlesOut[index].particles.velocity = particlesIn[index].particles.velocity;
// 在窗口边界翻转运动
if ((particlesOut[index].particles.position.x <= -1.0) || (particlesOut[index].particles.position.x >= 1.0)) {
particlesOut[index].particles.velocity.x = -particlesOut[index].particles.velocity.x;
}
if ((particlesOut[index].particles.position.y <= -1.0) || (particlesOut[index].particles.position.y >= 1.0)) {
particlesOut[index].particles.velocity.y = -particlesOut[index].particles.velocity.y;
}
}着色器的顶部包含着色器输入的声明。 首先是绑定0处的统一缓冲区对象,这是我们在本教程中已经学到的。 下面是我们声明与C++代码中的声明匹配的粒子结构。 绑定1然后引用带有上一帧粒子数据的着色器存储缓冲区对象(参见描述符设置)。 绑定2指向当前帧的SSBO,这是我们将在本着色器中更新的那个。
一个有趣的事情是与计算空间相关的计算专用声明:
[numthreads(256,1,1)]这定义了当前工作组中此计算着色器的调用次数。 如前所述,这是计算空间的局部部分。 由于我们处理的是粒子的线性1D数组,我们只需要在`[numthreads(x,y,z)]`中为x维度指定一个数字。
`compMain`函数然后从上一帧的SSBO读取,并将更新的粒子位置写入当前帧的SSBO。 与其他着色器类型类似,计算着色器有自己的一组内置输入变量。 我们传入的ThreadId是一个变量,它唯一地标识当前计算着色器调用在整个当前调度中。 它通过`SV_DispatchThreadID`注释获得这种能力。 我们使用它来索引到我们的粒子数组中。
运行计算命令
调度
现在是时候实际告诉GPU做一些计算了。 这是通过在命令缓冲区中调用`computeCommandBuffers[currentFrame]→dispatch`来完成的。 虽然不完全正确,但调度对于计算就像`commandBuffers[currentFrame]→draw`这样的绘制调用对于图形一样。 这最多在三个维度上调度给定数量的计算工作项。
computeCommandBuffers[currentFrame]->begin({});
...
computeCommandBuffers[currentFrame]->bindPipeline(vk::PipelineBindPoint::eCompute, *computePipeline);
computeCommandBuffers[currentFrame]->bindDescriptorSets(vk::PipelineBindPoint::eCompute, *computePipelineLayout, 0, {computeDescriptorSets[currentFrame]}, {});
computeCommandBuffers[currentFrame]->dispatch( PARTICLE_COUNT / 256, 1, 1 );
...
computeCommandBuffers[currentFrame]->end();computeCommandBuffers[currentFrame]→dispatch`将在x维度上调度`PARTICLE_COUNT / 256`个局部工作组。
由于我们的粒子数组是线性的,我们将其他两个维度保留为1,从而产生一维调度。
但为什么我们将粒子数量(在我们的数组中)除以256?
这是因为在前一段中,我们定义了工作组中的每个计算着色器将执行256次调用。
因此,如果我们有4096个粒子,我们将调度16个工作组,每个工作组运行256次计算着色器调用。
根据您的工作负载和运行的硬件,正确获取这两个数字通常需要一些调整和分析。
如果您的粒子大小是动态的,并且不能总是被例如256整除,您始终可以在计算着色器的开头使用`gl_GlobalInvocationID,并在全局调用索引大于粒子数量时返回。
与计算管线一样,计算命令缓冲区的状态比图形命令缓冲区少得多。 不需要启动渲染通道或设置视口。
提交工作
由于我们的示例同时进行计算和图形操作,我们将每帧向图形和计算队列提交两次(参见`drawFrame`函数):
...
computeQueue->submit(submitInfo, **computeInFlightFences[currentFrame]);
...
graphicsQueue->submit(submitInfo, **inFlightFences[currentFrame]);第一次提交到计算队列使用计算着色器更新粒子位置,第二次提交将使用更新的数据绘制粒子系统。
同步图形和计算
同步是Vulkan的重要组成部分,在进行计算与图形结合时更是如此。 错误或缺乏同步可能导致顶点阶段开始绘制(=读取)粒子,而计算着色器尚未完成更新(=写入)它们(读后写危险),或者计算着色器可能开始更新仍在管线顶点部分使用的粒子(写后读危险)。
因此,我们必须通过正确同步图形和计算负载来确保这些情况不会发生。 根据您提交计算工作负载的方式,有不同的方法可以做到这一点,但在我们的情况下,有两个单独的提交,我们将使用 信号量和 栅栏来确保顶点着色器在计算着色器完成更新之前不会开始获取顶点。
这是必要的,因为即使两个提交是按顺序一个接一个的,也不能保证它们在GPU上按此顺序执行。 添加等待和信号信号量可确保此执行顺序。
因此,我们首先在`createSyncObjects`中为计算工作添加一组新的同步原语。 计算栅栏,就像图形栅栏一样,创建在信号状态中,因为否则第一次绘制将在等待栅栏被信号时超时,如 此处详细说明:
std::vector<std::unique_ptr<vk::raii::Fence>> computeInFlightFences;
std::vector<std::unique_ptr<vk::raii::Semaphore>> computeFinishedSemaphores;
...
computeInFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
computeFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
...
computeFinishedSemaphores[i] = std::make_unique<vk::raii::Semaphore>(*device, vk::SemaphoreCreateInfo());
computeInFlightFences[i] = std::make_unique<vk::raii::Fence>(*device, vk::FenceCreateInfo(vk::FenceCreateFlagBits::eSignaled));
}然后我们使用这些来同步计算缓冲区提交与图形提交:
{
// 计算提交
while ( vk::Result::eTimeout == device->waitForFences( **computeInFlightFences[currentFrame], vk::True, FenceTimeout ) )
;
updateUniformBuffer(currentFrame);
device->resetFences( **computeInFlightFences[currentFrame] );
computeCommandBuffers[currentFrame]->reset();
recordComputeCommandBuffer();
const vk::SubmitInfo submitInfo({}, {}, {**computeCommandBuffers[currentFrame]}, { **computeFinishedSemaphores[currentFrame]});
computeQueue->submit(submitInfo, **computeInFlightFences[currentFrame]);
}
{
// 图形提交
while ( vk::Result::eTimeout == device->waitForFences( **inFlightFences[currentFrame], vk::True, FenceTimeout ) )
...
device->resetFences( **inFlightFences[currentFrame] );
commandBuffers[currentFrame]->reset();
recordCommandBuffer(imageIndex);
vk::Semaphore waitSemaphores[] = {**presentCompleteSemaphore[currentFrame], **computeFinishedSemaphores[currentFrame]};
vk::PipelineStageFlags waitDestinationStageMask[] = { vk::PipelineStageFlagBits::eVertexInput, vk::PipelineStageFlagBits::eColorAttachmentOutput };
const vk::SubmitInfo submitInfo( waitSemaphores, waitDestinationStageMask, {**commandBuffers[currentFrame]}, {**renderFinishedSemaphore[currentFrame]} );
graphicsQueue->submit(submitInfo, **inFlightFences[currentFrame]);与信号量章节中的示例类似,此设置将立即运行计算着色器,因为我们没有指定任何等待信号量。 请注意,我们在上面使用作用域大括号来确保我们在计算和图形阶段之间使用的RAII临时变量有机会清理自己。 这很好,因为我们正在等待当前帧的计算命令缓冲区完成执行,然后再使用`device→waitForFences`命令进行计算提交。
另一方面,图形提交需要等待计算工作完成,以便在计算缓冲区仍在更新顶点时不会开始获取顶点。 因此,我们等待当前帧的`computeFinishedSemaphores`,并让图形提交在`vk::PipelineStageFlagBits::eVertexInput`阶段等待,这是消耗顶点的阶段。
但它还需要等待呈现,以便片段着色器在图像呈现之前不会输出到颜色附件。 因此,我们还在当前帧的`vk::PipelineStageFlagBits::eColorAttachmentOutput`阶段等待`imageAvailableSemaphores`。
时间线信号量:改进的同步机制
上述同步方法使用二进制信号量,它们具有简单的信号/非信号状态。虽然这在许多场景中效果很好,但Vulkan还提供了一个更强大的同步原语:时间线信号量。
时间线信号量最初是作为扩展引入的,后来在Vulkan 1.2中提升为核心功能。与二进制信号量不同,时间线信号量具有一个64位无符号整数计数器值,可以等待和信号到特定值。这提供了几个优于二进制信号量的优势:
-
可重用性:单个时间线信号量可以用于多个同步点,减少了所需的信号量数量。
-
主机同步:时间线信号量可以从主机(CPU)信号和等待,而无需向队列提交命令。
-
无序信号:您可以将时间线信号量信号到高于当前等待的值,从而实现更灵活的同步模式。
-
多个待处理信号:与二进制信号量不同,二进制信号量只能待处理信号一次,而时间线信号量可以有多个待处理信号。
让我们看看如何修改我们的粒子系统示例以使用时间线信号量而不是二进制信号量:
首先,我们需要在创建逻辑设备时启用时间线信号量功能:
vk::PhysicalDeviceTimelineSemaphoreFeaturesKHR timelineSemaphoreFeatures;
timelineSemaphoreFeatures.timelineSemaphore = vk::True;
// 将此链接到您的设备创建信息我们不是创建多个二进制信号量,而是创建一个时间线信号量:
vk::SemaphoreTypeCreateInfo semaphoreType{ .semaphoreType = vk::SemaphoreType::eTimeline, .initialValue = 0 };
semaphore = vk::raii::Semaphore(device, {.pNext = &semaphoreType});
timelineValue = 0;在我们的绘制帧函数中,我们使用递增的时间线值来协调计算和图形之间的工作:
// 更新此帧的时间线值
uint64_t computeWaitValue = timelineValue;
uint64_t computeSignalValue = ++timelineValue;
uint64_t graphicsWaitValue = computeSignalValue;
uint64_t graphicsSignalValue = ++timelineValue;对于计算提交,我们使用时间线信号量提交信息结构:
vk::TimelineSemaphoreSubmitInfo computeTimelineInfo{
.waitSemaphoreValueCount = 1,
.pWaitSemaphoreValues = &computeWaitValue,
.signalSemaphoreValueCount = 1,
.pSignalSemaphoreValues = &computeSignalValue
};
vk::PipelineStageFlags waitStages[] = {vk::PipelineStageFlagBits::eComputeShader};
vk::SubmitInfo computeSubmitInfo{
.pNext = &computeTimelineInfo,
.waitSemaphoreCount = 1,
.pWaitSemaphores = &*semaphore,
.pWaitDstStageMask = waitStages,
.commandBufferCount = 1,
.pCommandBuffers = &*computeCommandBuffers[currentFrame],
.signalSemaphoreCount = 1,
.pSignalSemaphores = &*semaphore
};
computeQueue.submit(computeSubmitInfo, nullptr);类似地,对于图形提交:
vk::PipelineStageFlags waitStage = vk::PipelineStageFlagBits::eVertexInput;
vk::TimelineSemaphoreSubmitInfo graphicsTimelineInfo{
.waitSemaphoreValueCount = 1,
.pWaitSemaphoreValues = &graphicsWaitValue,
.signalSemaphoreValueCount = 1,
.pSignalSemaphoreValues = &graphicsSignalValue
};
vk::SubmitInfo graphicsSubmitInfo{
.pNext = &graphicsTimelineInfo,
.waitSemaphoreCount = 1,
.pWaitSemaphores = &*semaphore,
.pWaitDstStageMask = &waitStage,
.commandBufferCount = 1,
.pCommandBuffers = &*commandBuffers[currentFrame],
.signalSemaphoreCount = 1,
.pSignalSemaphores = &*semaphore
};
graphicsQueue.submit(graphicsSubmitInfo, nullptr);在呈现之前,我们等待图形工作完成:
vk::SemaphoreWaitInfo waitInfo{
.semaphoreCount = 1,
.pSemaphores = &*semaphore,
.pValues = &graphicsSignalValue
};
// 在呈现之前等待图形完成
while (vk::Result::eTimeout == device.waitSemaphores(waitInfo, UINT64_MAX))
;
vk::PresentInfoKHR presentInfo{
.waitSemaphoreCount = 0, // 不需要二进制信号量
.pWaitSemaphores = nullptr,
.swapchainCount = 1,
.pSwapchains = &*swapChain,
.pImageIndices = &imageIndex
};这种时间线信号量方法比二进制信号量实现提供了几个好处:
-
简化的资源管理:我们只需要一个信号量,而不是每帧飞行中的多个信号量。
-
更明确的同步:时间线值清楚地显示了哪些操作相互依赖。
-
减少开销:由于同步对象更少,管理它们的开销也更小。
-
更灵活的同步模式:时间线信号量支持更复杂的同步场景,这些场景在二进制信号量下会很难实现。
时间线信号量在具有多个依赖操作的场景中特别有用,例如我们的计算然后图形工作流,或者当您需要在主机和设备之间同步时。它们提供了一个更强大和灵活的同步机制,可以简化您的代码,同时支持更复杂的同步模式。
绘制粒子系统
早些时候,我们了解到Vulkan中的缓冲区可以有多种用途,因此我们创建了包含粒子的着色器存储缓冲区,其中包含着色器存储缓冲区位和顶点缓冲区位。 这意味着我们可以像在前几章中使用“纯”顶点缓冲区一样使用着色器存储缓冲区进行绘制。
我们首先设置顶点输入状态以匹配我们的粒子结构:
struct Particle {
...
static std::array<vk::VertexInputAttributeDescription, 2> getAttributeDescriptions() {
return {
vk::VertexInputAttributeDescription( 0, 0, vk::Format::eR32G32Sfloat, offsetof(Particle, position) ),
vk::VertexInputAttributeDescription( 1, 0, vk::Format::eR32G32B32A32Sfloat, offsetof(Particle, color) ),
};
}
};请注意,我们没有将`velocity`添加到顶点输入属性中,因为这仅由计算着色器使用。
然后我们像使用任何顶点缓冲区一样绑定和绘制它:
commandBuffers[currentFrame]->bindVertexBuffers(0, { *shaderStorageBuffers[currentFrame] }, {0});
commandBuffers[currentFrame]->draw( PARTICLE_COUNT, 1, 0, 0 );