渲染与呈现
本章将把所有内容整合在一起。我们将编写 drawFrame 函数,该函数将从主循环中调用以将三角形显示在屏幕上。让我们从创建该函数并在 mainLoop 中调用它开始:
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
}
...
void drawFrame() {
}帧的概述
在高层面上,Vulkan 中渲染一帧包括以下常见步骤:
-
等待前一帧完成
-
从交换链获取一个图像
-
记录一个命令缓冲区,将场景绘制到该图像上
-
提交记录的命令缓冲区
-
呈现交换链图像
虽然我们将在后续章节中扩展绘制函数,但目前这是渲染循环的核心。
同步
Vulkan 的核心设计理念之一是 GPU 上的执行同步是显式的。操作的顺序由我们使用各种同步原语定义,以告诉驱动程序我们希望操作的运行顺序。这意味着许多在 GPU 上启动工作的 Vulkan API 调用是异步的,函数会在操作完成之前返回。
在本章中,有许多事件需要显式排序,因为它们发生在 GPU 上,例如:
-
从交换链获取图像
-
执行绘制到获取的图像上的命令
-
将该图像呈现到屏幕上,并将其返回给交换链
这些事件中的每一个都是通过单个函数调用启动的,但都是异步执行的。函数调用会在操作实际完成之前返回,并且执行顺序也是未定义的。这很不幸,因为每个操作都依赖于前一个操作的完成。因此,我们需要探索可以使用哪些原语来实现所需的顺序。
信号量
二进制信号量用于在队列操作之间添加顺序。队列操作指的是我们提交到队列的工作,无论是在命令缓冲区中还是稍后将在函数中看到的。队列的示例包括图形队列和呈现队列。信号量既用于在同一队列内排序工作,也用于在不同队列之间排序工作。
Vulkan 中恰好有两种信号量:二进制信号量和时间线信号量。由于本教程中仅使用二进制信号量,因此我们不会讨论时间线信号量。后续提到的“信号量”一词均指二进制信号量。
二进制信号量要么是未发出信号的,要么是已发出信号的。它初始时为未发出信号的状态。我们使用二进制信号量对队列操作进行排序的方式是在一个队列操作中将其作为“发出信号”的信号量提供,而在另一个队列操作中将其作为“等待”的信号量提供。例如,假设我们有信号量 S 和队列操作 A 和 B,我们希望按顺序执行它们。我们告诉 Vulkan 的是,操作 A 将在执行完成后“发出信号”信号量 S,而操作 B 将在开始执行之前“等待”信号量 S。当操作 A 完成时,信号量 S 将被发出信号,而操作 B 在 S 被发出信号之前不会开始。操作 B 开始执行后,信号量 S 会自动重置为未发出信号的状态,以便可以再次使用。
伪代码如下:
VkCommandBuffer A, B = ... // 记录命令缓冲区 VkSemaphore S = ... // 创建信号量 // 将 A 加入队列,完成后发出信号 S - 立即开始执行 vkQueueSubmit(work: A, signal: S, wait: None) // 将 B 加入队列,等待 S 开始 vkQueueSubmit(work: B, signal: None, wait: S)
注意,在此代码片段中,两个 vkQueueSubmit() 调用都会立即返回 - 等待仅在 GPU 上发生。CPU 继续运行而不会阻塞。要让 CPU 等待,我们需要另一个同步原语,接下来将介绍。
栅栏
栅栏的用途类似,用于同步执行,但它是为了对 CPU(也称为主机)上的执行进行排序。具体来说,如果主机需要知道 GPU 何时完成某项工作,我们会使用栅栏。
与信号量类似,栅栏要么是已发出信号的,要么是未发出信号的。每当我们将工作提交执行时,可以将栅栏附加到该工作。当工作完成时,栅栏将被发出信号。然后我们可以让主机等待栅栏发出信号,以确保工作已完成后再继续。
一个具体的例子是截图。假设我们已经在 GPU 上完成了必要的工作。现在需要将图像从 GPU 传输到主机,然后将内存保存到文件中。我们有执行传输的命令缓冲区 A 和栅栏 F。我们提交命令缓冲区 A 并附带栅栏 F,然后立即告诉主机等待 F 发出信号。这会导致主机阻塞,直到命令缓冲区 A 完成执行。因此,我们可以安全地让主机将文件保存到磁盘,因为内存传输已完成。
伪代码如下:
VkCommandBuffer A = ... // 记录包含传输的命令缓冲区 VkFence F = ... // 创建栅栏 // 将 A 加入队列,立即开始工作,完成后发出信号 F vkQueueSubmit(work: A, fence: F) vkWaitForFence(F) // 阻塞执行,直到 A 完成执行 save_screenshot_to_disk() // 在传输完成之前无法运行
与信号量示例不同,此示例确实会阻塞主机执行。这意味着主机除了等待执行完成外不会做任何事情。对于这种情况,我们必须确保传输完成才能将截图保存到磁盘。
一般来说,除非必要,否则最好不要阻塞主机。我们希望为 GPU 和主机提供有用的工作。等待栅栏发出信号并不是有用的工作。因此,我们更倾向于使用信号量或其他尚未介绍的同步原语来同步工作。
栅栏必须手动重置以将其恢复为未发出信号的状态。这是因为栅栏用于控制主机的执行,因此主机可以决定何时重置栅栏。相比之下,信号量用于在主机不参与的情况下对 GPU 上的工作进行排序。
总结一下,信号量用于指定 GPU 上操作的执行顺序,而栅栏用于保持 CPU 和 GPU 之间的同步。
创建同步对象
我们需要一个信号量来表示已从交换链获取图像并准备好进行渲染。另一个信号量表示渲染已完成,可以进行呈现。还需要一个栅栏来确保一次只渲染一帧。
创建三个类成员来存储这些信号量对象和栅栏对象:
vk::raii::Semaphore presentCompleteSemaphore = nullptr;
vk::raii::Semaphore renderFinishedSemaphore = nullptr;
vk::raii::Fence drawFence = nullptr;为了创建信号量,我们将为本教程部分添加最后一个 create 函数:createSyncObjects:
void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createGraphicsPipeline();
createCommandPool();
createCommandBuffer();
createSyncObjects();
}
...
void createSyncObjects() {
}创建信号量需要填写 VkSemaphoreCreateInfo,但在当前版本的 API 中,除了 sType 外,它实际上没有任何必填字段:
void createSyncObjects() {
presentCompleteSemaphore = vk::raii::Semaphore(device, vk::SemaphoreCreateInfo());
renderFinishedSemaphore = vk::raii::Semaphore(device, vk::SemaphoreCreateInfo());
drawFence = vk::raii::Fence(device, {.flags = vk::FenceCreateFlagBits::eSignaled});
}Vulkan API 的未来版本或扩展可能会为 flags 和 pNext 参数添加功能,就像对其他结构所做的那样。
进入主绘制函数!
等待前一帧
在帧开始时,我们希望等待前一帧完成,以便命令缓冲区和信号量可用。为此,我们调用 vkWaitForFences:
void drawFrame() {
auto [result, imageIndex] = swapChain.acquireNextImage( UINT64_MAX, *presentCompleteSemaphore, nullptr );
}首先,在前一帧完成后,我们从帧缓冲区获取一个图像。vkAcquireNextImageKHR 的前两个参数是逻辑设备和我们要从中获取图像的交换链。第三个参数指定图像可用的超时时间(以纳秒为单位)。使用 64 位无符号整数的最大值意味着我们实际上禁用了超时。
接下来的两个参数指定在呈现引擎完成使用图像时要发出信号的同步对象。这是我们可以开始绘制到图像上的时间点。可以指定信号量、栅栏或两者。我们在这里使用 imageAvailableSemaphore 来实现这一目的。
最后一个参数指定一个变量,用于输出已可用的交换链图像的索引。该索引对应于 swapChainImages 数组中的 VkImage。我们将使用该索引来选择 VkFrameBuffer,然后记录到该帧缓冲区中。
vkWaitForFences 函数接受一个栅栏数组,并在主机上等待任何一个或所有栅栏发出信号后再返回。我们在此传递的 VK_TRUE 表示我们希望等待所有栅栏,但对于单个栅栏来说无关紧要。此函数还有一个超时参数,我们将其设置为 64 位无符号整数的最大值 UINT64_MAX,从而有效地禁用超时。
记录命令缓冲区
有了指定要使用的交换链图像的 imageIndex,我们现在可以记录命令缓冲区。现在调用函数 recordCommandBuffer 来记录我们需要的命令。
recordCommandBuffer(imageIndex);我们需要确保如果前一帧已经完成,栅栏会被重置,以便稍后等待它。
device.resetFences( *drawFence );有了完全记录的命令缓冲区,我们现在可以提交它。
提交命令缓冲区
队列提交和同步通过 VkSubmitInfo 结构中的参数配置。
vk::PipelineStageFlags waitDestinationStageMask( vk::PipelineStageFlagBits::eColorAttachmentOutput );
const vk::SubmitInfo submitInfo( **presentCompleteSemaphore, waitDestinationStageMask, **commandBuffer, **renderFinishedSemaphore );前三个参数指定在执行开始之前要等待的信号量以及在管线的哪些阶段等待。我们希望等待直到图像可用后才开始写入颜色,因此我们指定图形管线中写入颜色附件的阶段。这意味着理论上,实现可以在图像还不可用时已经开始执行顶点着色器等操作。waitStages 数组中的每个条目对应于 pWaitSemaphores 中相同索引的信号量。
下一个参数指定实际要提交执行的命令缓冲区。我们只需提交我们拥有的单个命令缓冲区。
pSignalSemaphores 参数指定命令缓冲区完成后要发出信号的信号量。在我们的例子中,我们使用 renderFinishedSemaphore 来实现这一目的。
graphicsQueue.submit(submitInfo, *drawFence);我们现在可以使用 vkQueueSubmit 将命令缓冲区提交到图形队列。该函数接受一个 VkSubmitInfo 结构数组作为参数,以便在工作负载较大时提高效率。最后一个参数引用一个可选的栅栏,该栅栏将在命令缓冲区完成执行时发出信号。这使我们知道何时可以安全地重用命令缓冲区,因此我们希望给它 drawFence。现在我们希望 CPU 等待 GPU 完成我们刚刚提交的帧的渲染:
while ( vk::Result::eTimeout == device.waitForFences( *drawFence, vk::True, UINT64_MAX ) )
;子通道依赖
本节是可选的,并且比必要的更加显式。
请记住,渲染通道中的子通道会自动处理图像布局转换。这些转换由_子通道依赖_控制,它指定子通道之间的内存和执行依赖关系。我们现在只有一个子通道,但该子通道之前和之后的操作也算作隐式的“子通道”。
有两个内置依赖关系负责渲染通道开始和结束时的转换,但前者没有在正确的时间发生。它假设转换发生在管线的开始,但在那时我们还没有获取图像!有两种方法可以解决这个问题。我们可以将 imageAvailableSemaphore 的 waitStages 更改为 VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT 以确保渲染通道在图像可用之前不会开始,或者我们可以让渲染通道等待 VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT 阶段。我决定在这里使用第二种选项,因为这是一个很好的机会来了解子通道依赖关系及其工作原理。
子通道依赖关系在 VkSubpassDependency 结构中指定。转到 createRenderPass 函数并添加一个:
vk::SubpassDependency dependency(VK_SUBPASS_EXTERNAL, {});前两个字段指定依赖关系和依赖子通道的索引。特殊值 VK_SUBPASS_EXTERNAL 指的是渲染通道之前或之后的隐式子通道,具体取决于它是在 srcSubpass 还是 dstSubpass 中指定的。索引 0 指的是我们的子通道,它是第一个也是唯一一个。dstSubpass 必须始终高于 srcSubpass 以防止依赖关系图中的循环(除非其中一个子通道是 VK_SUBPASS_EXTERNAL)。
vk::SubpassDependency dependency(VK_SUBPASS_EXTERNAL, {},
vk::PipelineStageFlagBits::eColorAttachmentOutput, vk::PipelineStageFlagBits::eColorAttachmentOutput,
{}, vk::AccessFlagBits::eColorAttachmentWrite);接下来的两个字段指定要等待的操作以及应在颜色附件阶段等待这些操作。最后两个字段指定这些操作发生的阶段,并涉及颜色附件的写入。我们需要等待交换链完成从图像中读取后才能访问它。这可以通过等待颜色附件输出阶段本身来实现。
这些设置将防止转换在实际需要(并且允许)时发生:当我们想要开始向其写入颜色时。
renderPassInfo.dependencyCount = 1;
renderPassInfo.pDependencies = &dependency;VkRenderPassCreateInfo 结构有两个字段用于指定依赖关系数组。
以上内容完全是可选的,并未在 演示代码中重现。
呈现
绘制帧的最后一步是将结果提交回交换链,最终显示在屏幕上。呈现通过 drawFrame 函数末尾的 VkPresentInfoKHR 结构配置。
const vk::PresentInfoKHR presentInfoKHR( **renderFinishedSemaphore, **swapChain, imageIndex );前两个参数指定在呈现之前要等待的信号量,就像 VkSubmitInfo 一样。由于我们希望等待命令缓冲区完成执行(即绘制三角形),因此我们使用将被发出信号的信号量并等待它们,因此我们使用 signalSemaphores。
接下来的两个参数指定要呈现图像的交换链以及每个交换链的图像索引。这几乎总是单一的。
presentInfo.pResults = nullptr; // 可选还有一个名为 pResults 的可选参数。它允许您为每个交换链指定一个 VkResult 值数组,以检查呈现是否成功。如果仅使用单个交换链,则不需要它,因为您可以使用呈现函数的返回值。
result = presentQueue.presentKHR( presentInfoKHR );vkQueuePresentKHR 函数提交将图像呈现到交换链的请求。我们将在下一章中添加对 vkAcquireNextImageKHR 和 vkQueuePresentKHR 的错误处理,因为它们的失败并不一定意味着程序应该终止,这与我们目前看到的函数不同。
如果您到目前为止一切正确,那么现在运行程序时应该会看到类似以下内容:
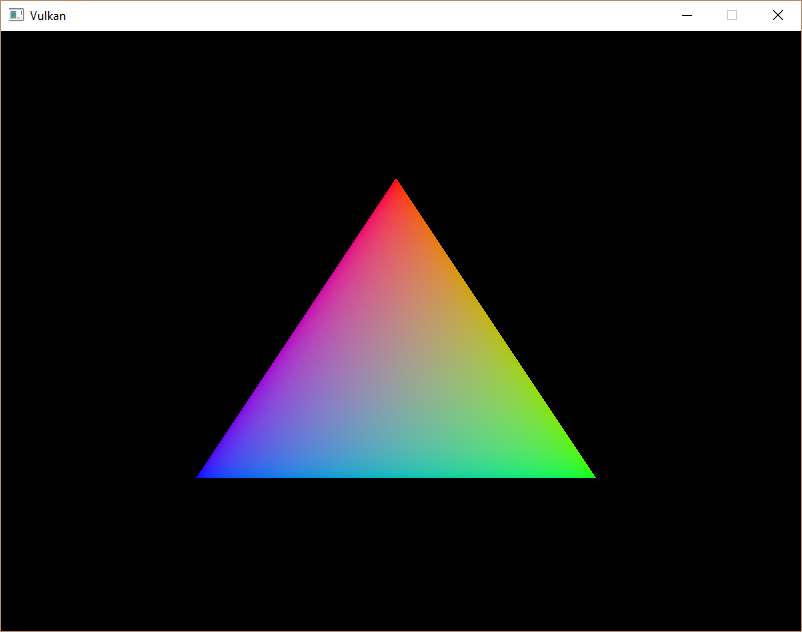
这个彩色三角形可能与您在图形教程中习惯看到的三角形略有不同。这是因为本教程允许着色器在线性颜色空间中进行插值,然后转换为 sRGB 颜色空间。
耶!
不幸的是,您会发现当启用验证层时,程序在关闭时会崩溃。debugCallback 打印到终端的消息告诉我们原因:

请记住,drawFrame 中的所有操作都是异步的。这意味着当我们退出 mainLoop 中的循环时,绘制和呈现操作可能仍在进行。在这种情况下清理资源是一个坏主意。
要解决此问题,我们应该在退出 mainLoop 并销毁窗口之前等待逻辑设备完成操作:
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
device.waitIdle();
}您还可以使用 vkQueueWaitIdle 等待特定命令队列中的操作完成。这些函数可以用作执行同步的非常基本的方式。您会发现现在关闭窗口时程序可以正常退出。
结论
在编写了 500 多行代码之后,我们终于到了在屏幕上看到东西的阶段!启动 Vulkan 程序绝对是一项繁重的工作,但关键信息是 Vulkan 通过其显式性为您提供了巨大的控制权。我建议您现在花一些时间重新阅读代码,并构建一个关于程序中所有 Vulkan 对象的目的及其相互关系的心理模型。我们将在此基础上扩展程序的功能。
此外,在未来的章节中,我们将讨论时间线信号量和内存屏障,并进一步完善我们对 Vulkan 中同步的理解。同步是利用 Vulkan 真正强大功能的最大领域之一,因此它相当复杂。虽然第一次理解时很复杂,但这确实是接下来内容的基础。从这里开始,当您有更多工具来执行更细微的操作时,事情会变得更容易。
下一章将扩展渲染循环以处理多帧在飞行中的情况。
C++ 代码 / Slang 着色器 / GLSL 顶点着色器 / GLSL 片段着色器