深度缓冲
简介
到目前为止,我们处理的几何图形虽然投影到了3D空间中,但仍然完全是平面的。 在本章中,我们将为位置添加一个Z坐标,为3D网格做准备。 我们将使用这个第三坐标在当前正方形上方放置另一个正方形,以展示当几何图形未按深度排序时出现的问题。
3D几何图形
将 Vertex 结构体改为使用3D向量表示位置,并更新对应的 VkVertexInputAttributeDescription 中的 format:
struct Vertex {
glm::vec3 pos;
glm::vec3 color;
glm::vec2 texCoord;
...
static std::array<vk::VertexInputAttributeDescription, 3> getAttributeDescriptions() {
return {
vk::VertexInputAttributeDescription( 0, 0, vk::Format::eR32G32B32Sfloat, offsetof(Vertex, pos) ),
vk::VertexInputAttributeDescription( 1, 0, vk::Format::eR32G32B32Sfloat, offsetof(Vertex, color) ),
vk::VertexInputAttributeDescription( 2, 0, vk::Format::eR32G32Sfloat, offsetof(Vertex, texCoord) )
};
...
}
};接下来,更新顶点着色器以接受并变换3D坐标作为输入。 记得之后重新编译它!
float3 inPosition;
...
[shader("vertex")]
VSOutput vertMain(VSInput input) {
VSOutput output;
output.pos = mul(ubo.proj, mul(ubo.view, mul(ubo.model, float4(input.inPosition, 1.0))));
output.fragColor = input.inColor;
output.fragTexCoord = input.inTexCoord;
return output;
}最后,更新 vertices 容器以包含Z坐标:
const std::vector<Vertex> vertices = {
{{-0.5f, -0.5f, 0.0f}, {1.0f, 0.0f, 0.0f}, {0.0f, 0.0f}},
{{0.5f, -0.5f, 0.0f}, {0.0f, 1.0f, 0.0f}, {1.0f, 0.0f}},
{{0.5f, 0.5f, 0.0f}, {0.0f, 0.0f, 1.0f}, {1.0f, 1.0f}},
{{-0.5f, 0.5f, 0.0f}, {1.0f, 1.0f, 1.0f}, {0.0f, 1.0f}}
};如果现在运行应用程序,你应该会看到与之前完全相同的结果。 是时候添加一些额外的几何图形来使场景更有趣,并展示我们将在本章中解决的问题。 复制顶点以定义当前正方形下方的另一个正方形的位置,如下所示:

使用 -0.5f 的Z坐标,并为额外的正方形添加适当的索引:
const std::vector<Vertex> vertices = {
{{-0.5f, -0.5f, 0.0f}, {1.0f, 0.0f, 0.0f}, {0.0f, 0.0f}},
{{0.5f, -0.5f, 0.0f}, {0.0f, 1.0f, 0.0f}, {1.0f, 0.0f}},
{{0.5f, 0.5f, 0.0f}, {0.0f, 0.0f, 1.0f}, {1.0f, 1.0f}},
{{-0.5f, 0.5f, 0.0f}, {1.0f, 1.0f, 1.0f}, {0.0f, 1.0f}},
{{-0.5f, -0.5f, -0.5f}, {1.0f, 0.0f, 0.0f}, {0.0f, 0.0f}},
{{0.5f, -0.5f, -0.5f}, {0.0f, 1.0f, 0.0f}, {1.0f, 0.0f}},
{{0.5f, 0.5f, -0.5f}, {0.0f, 0.0f, 1.0f}, {1.0f, 1.0f}},
{{-0.5f, 0.5f, -0.5f}, {1.0f, 1.0f, 1.0f}, {0.0f, 1.0f}}
};
const std::vector<uint16_t> indices = {
0, 1, 2, 2, 3, 0,
4, 5, 6, 6, 7, 4
};现在运行程序,你会看到类似于埃舍尔插图的内容:
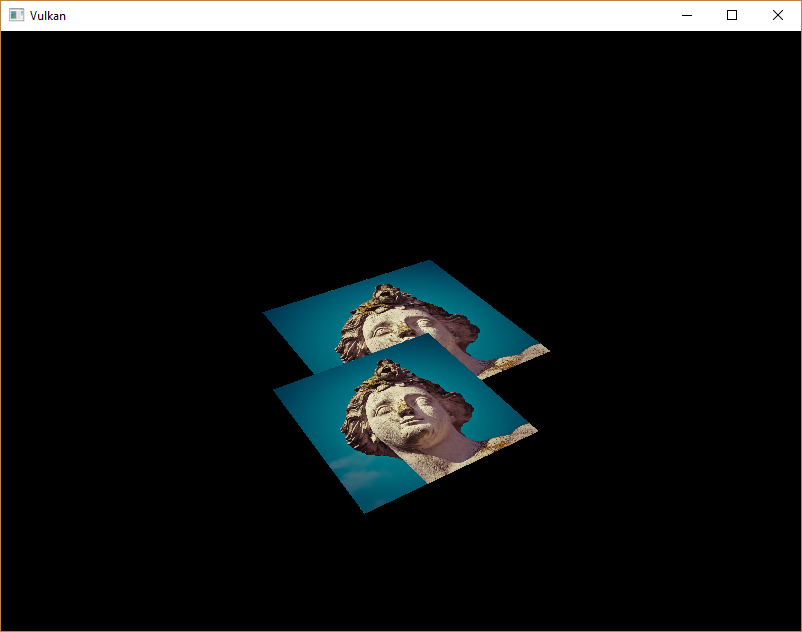
问题在于,下方正方形的片段被绘制在上方正方形的片段之上,仅仅因为它在索引数组中排在后面。 有两种方法可以解决这个问题:
-
将所有绘制调用按从后到前的深度排序
-
使用深度测试和深度缓冲
第一种方法通常用于绘制透明对象,因为顺序无关的透明度是一个难以解决的挑战。 然而,更常见的解决方案是使用_深度缓冲_来按深度排序片段。 深度缓冲是一个额外的附件,存储每个位置的深度,就像颜色附件存储每个位置的颜色一样。 每当光栅化器生成一个片段时,深度测试会检查新片段是否比之前的片段更近。 如果不是,则新片段会被丢弃。 通过深度测试的片段会将其深度写入深度缓冲。 可以从片段着色器中操作这个值,就像可以操作颜色输出一样。
#define GLM_FORCE_DEPTH_ZERO_TO_ONE
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>GLM生成的透视投影矩阵默认使用OpenGL的深度范围 -1.0 到 1.0。
我们需要配置它使用Vulkan的范围 0.0 到 1.0,通过 GLM_FORCE_DEPTH_ZERO_TO_ONE 定义。
深度图像和视图
深度附件基于图像,就像颜色附件一样。 区别在于交换链不会自动为我们创建深度图像。 我们只需要一个深度图像,因为一次只运行一个绘制操作。 深度图像再次需要三种资源:图像、内存和图像视图。
vk::raii::Image depthImage = nullptr;
vk::raii::DeviceMemory depthImageMemory = nullptr;
vk::raii::ImageView depthImageView = nullptr;创建一个新函数 createDepthResources 来设置这些资源:
void initVulkan() {
...
createCommandPool();
createDepthResources();
createTextureImage();
...
}
...
void createDepthResources() {
}创建深度图像相当简单。
它应该具有与颜色附件相同的分辨率,由交换链范围定义,适合深度附件的图像使用方式,最佳平铺和设备本地内存。
唯一的问题是:深度图像的正确格式是什么?
格式必须包含深度分量,由 VK_FORMAT_ 中的 D?? 表示。
与纹理图像不同,我们不一定需要特定的格式,因为我们不会直接从程序中访问纹理像素。 它只需要具有合理的精度,至少24位在现实应用中很常见。 有几种格式符合这一要求:
-
VK_FORMAT_D32_SFLOAT: 32位浮点数用于深度 -
VK_FORMAT_D32_SFLOAT_S8_UINT: 32位有符号浮点数用于深度和8位模板分量 -
VK_FORMAT_D24_UNORM_S8_UINT: 24位浮点数用于深度和8位模板分量
模板分量用于https://en.wikipedia.org/wiki/Stencil_buffer[模板测试],这是可以与深度测试结合使用的额外测试。 我们将在未来的章节中讨论这一点。
我们可以简单地选择 VK_FORMAT_D32_SFLOAT 格式,因为对它的支持非常普遍(参见硬件数据库),但在可能的情况下,为我们的应用程序增加一些灵活性是很好的。
我们将编写一个函数 findSupportedFormat,它接受一个候选格式列表,按从最理想到最不理想的顺序排列,并检查第一个支持的格式:
vk::Format findSupportedFormat(const std::vector<vk::Format>& candidates, vk::ImageTiling tiling, vk::FormatFeatureFlags features) {
}格式的支持取决于平铺模式和用途,因此我们还需要将这些作为参数。
可以使用 vkGetPhysicalDeviceFormatProperties 函数查询格式的支持情况:
for (const auto format : candidates) {
vk::FormatProperties props = physicalDevice.getFormatProperties(format);
}VkFormatProperties 结构体包含三个字段:
-
linearTilingFeatures: 线性平铺支持的使用场景 -
optimalTilingFeatures: 最佳平铺支持的使用场景 -
bufferFeatures: 缓冲区支持的使用场景
只有前两个在这里相关,我们检查哪一个取决于函数的 tiling 参数:
if (tiling == vk::ImageTiling::eLinear && (props.linearTilingFeatures & features) == features) {
return format;
}
if (tiling == vk::ImageTiling::eOptimal && (props.optimalTilingFeatures & features) == features) {
return format;
}如果没有候选格式支持所需的用途,则可以返回一个特殊值或直接抛出异常:
vk::Format findSupportedFormat(const std::vector<vk::Format>& candidates, vk::ImageTiling tiling, vk::FormatFeatureFlags features) {
for (const auto format : candidates) {
vk::FormatProperties props = physicalDevice.getFormatProperties(format);
if (tiling == vk::ImageTiling::eLinear && (props.linearTilingFeatures & features) == features) {
return format;
}
if (tiling == vk::ImageTiling::eOptimal && (props.optimalTilingFeatures & features) == features) {
return format;
}
}
throw std::runtime_error("failed to find supported format!");
}我们现在将使用这个函数来创建一个 findDepthFormat 辅助函数,以选择支持作为深度附件用途的包含深度分量的格式:
VkFormat findDepthFormat() {
return findSupportedFormat(
{vk::Format::eD32Sfloat, vk::Format::eD32SfloatS8Uint, vk::Format::eD24UnormS8Uint},
vk::ImageTiling::eOptimal,
vk::FormatFeatureFlagBits::eDepthStencilAttachment
);
}确保在这种情况下使用 VK_FORMAT_FEATURE_ 标志而不是 VK_IMAGE_USAGE_。
所有这些候选格式都包含深度分量,但后两个还包含模板分量。
我们暂时不会使用它,但在对这些格式的图像执行布局转换时需要考虑这一点。
添加一个简单的辅助函数,告诉我们选择的深度格式是否包含模板分量:
bool hasStencilComponent(vk::Format format) {
return format == vk::Format::eD32SfloatS8Uint || format == vk::Format::eD24UnormS8Uint;
}从 createDepthResources 调用函数以查找深度格式:
vk::Format depthFormat = findDepthFormat();我们现在拥有调用 createImage 和 createImageView 辅助函数所需的所有信息:
createImage(swapChainExtent.width, swapChainExtent.height, depthFormat, vk::ImageTiling::eOptimal, vk::ImageUsageFlagBits::eDepthStencilAttachment, vk::MemoryPropertyFlagBits::eDeviceLocal, depthImage, depthImageMemory);
depthImageView = createImageView(depthImage, depthFormat, vk::ImageAspectFlagBits::eDepth);然而,createImageView 函数目前假设子资源始终是 VK_IMAGE_ASPECT_COLOR_BIT,因此我们需要将该字段转换为参数:
vk::raii::ImageView createImageView(vk::raii::Image& image, vk::Format format, vk::ImageAspectFlags aspectFlags) {
...
viewInfo.subresourceRange.aspectMask = aspectFlags;
...
}更新所有调用此函数的地方以使用正确的方面:
swapChainImageViews[i] = createImageView(swapChainImages[i], swapChainImageFormat, vk::ImageAspectFlagBits::eColor);
...
depthImageView = createImageView(depthImage, depthFormat, vk::ImageAspectFlagBits::eDepth);
...
textureImageView = createImageView(textureImage, vk::Format::eR8G8B8A8Srgb, vk::ImageAspectFlagBits::eColor);这就是创建深度图像的全部内容。 我们不需要映射它或复制另一个图像到它,因为我们将在渲染通道开始时像颜色附件一样清除它。
显式转换深度图像
我们不需要显式地将图像的布局转换为深度附件,因为我们将在渲染通道中处理这一点。 然而,为了完整性,我仍然在本节中描述这个过程。 如果你愿意,可以跳过它。
在 createDepthResources 函数的末尾调用 transitionImageLayout,如下所示:
transitionImageLayout(depthImage, depthFormat, vk::ImageLayout::eUndefined, vk::ImageLayout::eTransferDstOptimal);可以使用未定义的布局作为初始布局,因为没有现有的深度图像内容重要。
我们需要更新 transitionImageLayout 中的一些逻辑以使用正确的子资源方面:
if (newLayout == vk::ImageLayout::eDepthStencilAttachmentOptimal) {
barrier.subresourceRange.aspectMask = vk::ImageAspectFlagBits::eDepth;
if (hasStencilComponent(format)) {
barrier.subresourceRange.aspectMask |= VK_IMAGE_ASPECT_STENCIL_BIT;
}
} else {
barrier.subresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
}虽然我们不使用模板分量,但我们确实需要在深度图像的布局转换中包含它。
最后,添加正确的访问掩码和管道阶段:
if (oldLayout == VK_IMAGE_LAYOUT_UNDEFINED && newLayout == VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL) {
barrier.srcAccessMask = 0;
barrier.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
sourceStage = VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT;
destinationStage = VK_PIPELINE_STAGE_TRANSFER_BIT;
} else if (oldLayout == VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL && newLayout == VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL) {
barrier.srcAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
barrier.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
sourceStage = VK_PIPELINE_STAGE_TRANSFER_BIT;
destinationStage = VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT;
} else if (oldLayout == VK_IMAGE_LAYOUT_UNDEFINED && newLayout == VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL) {
barrier.srcAccessMask = 0;
barrier.dstAccessMask = VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_READ_BIT | VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_WRITE_BIT;
sourceStage = VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT;
destinationStage = VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT;
} else {
throw std::invalid_argument("unsupported layout transition!");
}深度缓冲将从读取以执行深度测试以查看片段是否可见,并在绘制新片段时写入。
读取发生在 VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT 阶段,写入发生在 VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT。
你应该选择与指定操作匹配的最早管道阶段,以便在需要时准备好作为深度附件使用。
渲染通道
我们现在将修改 createRenderPass 以包含深度附件。
首先指定 VkAttachmentDescription:
vk::AttachmentDescription depthAttachment({}, findDepthFormat(), vk::SampleCountFlagBits::e1, vk::AttachmentLoadOp::eClear,
vk::AttachmentStoreOp::eDontCare, vk::AttachmentLoadOp::eDontCare, vk::AttachmentStoreOp::eDontCare, vk::ImageLayout::eUndefined,
vk::ImageLayout::eDepthStencilAttachmentOptimal);format 应与深度图像本身相同。
这次我们不关心存储深度数据(storeOp),因为它不会在绘制完成后使用。
这可能允许硬件执行额外的优化。
就像颜色缓冲一样,我们不关心之前的深度内容,因此可以使用 VK_IMAGE_LAYOUT_UNDEFINED 作为 initialLayout。
vk::AttachmentReference depthAttachmentRef(1, vk::ImageLayout::eDepthStencilAttachmentOptimal);为第一个(也是唯一一个)子通道添加对附件的引用:
vk::SubpassDescription subpass({}, vk::PipelineBindPoint::eGraphics, 0, {}, 1, &colorAttachmentRef, {}, &depthAttachmentRef);与颜色附件不同,一个子通道只能使用一个深度(+模板)附件。 在多个缓冲上执行深度测试没有意义。
std::array attachments = {colorAttachment, depthAttachment};
vk::RenderPassCreateInfo renderPassInfo({}, attachments, subpass, dependency);接下来,更新 VkSubpassDependency 结构体以引用两个附件。
vk::SubpassDependency dependency(vk::SubpassExternal, {},
vk::PipelineStageFlagBits::eColorAttachmentOutput | vk::PipelineStageFlagBits::eLateFragmentTests,
vk::PipelineStageFlagBits::eEarlyFragmentTests | vk::PipelineStageFlagBits::eColorAttachmentOutput,
vk::AccessFlagBits::eDepthStencilAttachmentWrite,
vk::AccessFlagBits::eDepthStencilAttachmentWrite | vk::AccessFlagBits::eColorAttachmentWrite
);最后,我们需要扩展子通道依赖关系,以确保深度图像的转换与其作为加载操作的一部分被清除之间没有冲突。 深度图像首先在早期片段测试管道阶段被访问,因为我们有一个_清除_的加载操作,我们应该为写入指定访问掩码。
帧缓冲
下一步是修改帧缓冲创建以将深度图像绑定到深度附件。
转到 createFramebuffers 并指定深度图像视图作为第二个附件:
svk::ImageView attachments[] = { view, *depthImageView };
vk::FramebufferCreateInfo framebufferCreateInfo( {}, *renderPass, attachments, swapChainExtent.width, swapChainExtent.height, 1 );颜色附件对每个交换链图像都不同,但同一个深度图像可以被所有图像使用,因为由于我们的信号量,一次只运行一个子通道。
你还需要移动对 createFramebuffers 的调用,以确保在深度图像视图实际创建后调用它:
void initVulkan() {
...
createDepthResources();
createFramebuffers();
...
}清除值
因为我们现在有多个带有 VK_ATTACHMENT_LOAD_OP_CLEAR 的附件,所以还需要指定多个清除值。
转到 recordCommandBuffer 并创建一个 VkClearValue 结构体数组:
vk::ClearValue clearColor[2] = { vk::ClearColorValue(0.0f, 0.0f, 0.0f, 1.0f), vk::ClearDepthStencilValue(1.0f, 0) };
vk::RenderPassBeginInfo renderPassInfo( *renderPass, swapChainFramebuffers[imageIndex], {{0, 0}, swapChainExtent}, clearColor);深度缓冲中的深度范围在Vulkan中是 0.0 到 1.0,其中 1.0 位于远视图平面,0.0 位于近视图平面。
深度缓冲中每个点的初始值应该是最远的深度,即 1.0。
注意,clearValues 的顺序应与附件的顺序相同。
深度和模板状态
深度附件现在可以使用了,但仍然需要在图形管道中启用深度测试。
它通过 VkPipelineDepthStencilStateCreateInfo 结构体配置:
depthTestEnable 字段指定是否应将新片段的深度与深度缓冲进行比较以查看是否应丢弃它们。
depthWriteEnable 字段指定通过深度测试的新片段的深度是否应实际写入深度缓冲。
depthCompareOp 字段指定执行以保留或丢弃片段的比较。
我们坚持较低的深度=更近的约定,因此新片段的深度应该_更小_。
depthBoundsTestEnable、minDepthBounds 和 maxDepthBounds 字段用于可选的深度边界测试。
基本上,这允许你仅保留落在指定深度范围内的片段。
我们不会在本教程中使用此功能。
最后三个字段配置模板缓冲操作,我们也不会在本教程中使用它们。 如果你想使用这些操作,则需要确保深度/模板图像的格式包含模板分量。
更新 VkGraphicsPipelineCreateInfo 结构体以引用我们刚刚填充的深度模板状态。
如果渲染通道包含深度模板附件,则必须始终指定深度模板状态。
如果现在运行程序,你应该会看到几何图形的片段现在正确排序:
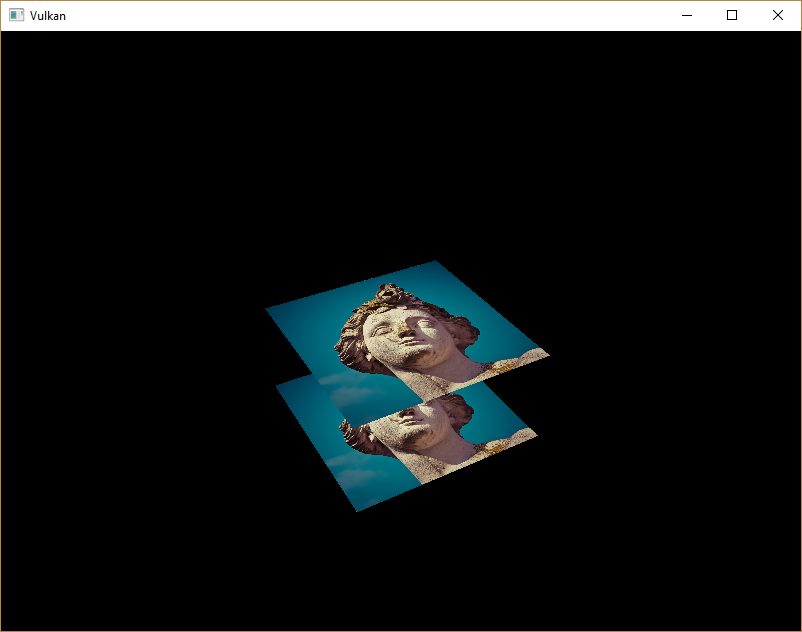
处理窗口调整大小
当窗口调整大小时,深度缓冲的分辨率应更改以匹配新的颜色附件分辨率。
扩展 recreateSwapChain 函数以在这种情况下重新创建深度资源:
void recreateSwapChain() {
int width = 0, height = 0;
while (width == 0 || height == 0) {
glfwGetFramebufferSize(window, &width, &height);
glfwWaitEvents();
}
vkDeviceWaitIdle(device);
cleanupSwapChain();
createSwapChain();
createImageViews();
createDepthResources();
createFramebuffers();
}恭喜,你的应用程序现在终于准备好渲染任意的3D几何图形并使其看起来正确。 我们将在下一章中通过绘制一个带纹理的模型来尝试这一点!