加载模型
介绍
您的程序现在已经准备好渲染带纹理的 3D 网格,但 vertices 和 indices 数组中的当前几何体还不是很有趣。
在本章中,我们将扩展程序,从实际的模型文件中加载顶点和索引,让图形卡真正开始工作。
许多图形 API 教程在这样的章节中会让读者编写自己的 OBJ 加载器。 这样做的问题是,任何稍微有趣的 3D 应用程序很快就会需要这种文件格式不支持的功能,比如骨骼动画。 我们 将会 在本章中从 OBJ 模型加载网格数据,但我们将更多地关注如何将网格数据与程序本身集成,而不是从文件加载它的细节。
库
我们将使用 tinyobjloader 库从 OBJ 文件加载顶点和面。 它很快,而且很容易集成,因为它是一个单文件库,就像 stb_image 一样。 这在 开发环境 章节中已经提到过,应该是本教程这部分依赖项的一部分。
示例网格
在本章中,我们还不会启用光照,所以使用一个将光照烘焙到纹理中的示例模型会有所帮助。 找到这类模型的一个简单方法是在 Sketchfab 上寻找 3D 扫描。 该网站上的许多模型都以 OBJ 格式提供,并带有宽松的许可证。
对于本教程,我决定使用 nigelgoh 的 Viking room 模型(https://web.archive.org/web/20200428202538/https://sketchfab.com/3d-models/viking-room-a49f1b8e4f5c4ecf9e1fe7d81915ad38[CC BY 4.0])。 我调整了模型的大小和方向,使其可以作为当前几何体的即插即用替代品:
{kind=link}
您可以随意使用自己的模型,但请确保它只包含一种材质,并且尺寸约为 1.5 x 1.5 x 1.5 单位。
如果它比这个更大,那么您将需要更改视图矩阵。
将模型文件放在 shaders 和 textures 旁边的新 models 目录中,并将纹理图像放在 textures 目录中。
在您的程序中添加两个新的配置变量来定义模型和纹理路径:
constexpr uint32_t WIDTH = 800;
constexpr uint32_t HEIGHT = 600;
constexpr uint64_t FenceTimeout = 100000000;
const std::string MODEL_PATH = "models/viking_room.obj";
const std::string TEXTURE_PATH = "textures/viking_room.png";并更新 createTextureImage 以使用这个路径变量:
stbi_uc* pixels = stbi_load(TEXTURE_PATH.c_str(), &texWidth, &texHeight, &texChannels, STBI_rgb_alpha);加载顶点和索引
我们现在将从模型文件中加载顶点和索引,所以您现在应该删除全局的 vertices 和 indices 数组。
用非常量容器作为类成员替换它们:
std::vector<Vertex> vertices;
std::vector<uint32_t> indices;
vk::raii::Buffer vertexBuffer = nullptr;
vk::raii::DeviceMemory vertexBufferMemory = nullptr;
vk::raii::Buffer indexBuffer = nullptr;
vk::raii::DeviceMemory indexBufferMemory = nullptr;您应该将索引的类型从 uint16_t 更改为 uint32_t,因为将会有比 65535 多得多的顶点。
记得也要更改 vkCmdBindIndexBuffer 参数:
commandBuffers[currentFrame]->bindIndexBuffer( **indexBuffer, 0, vk::IndexType::eUint32 );tinyobjloader 库的包含方式与 STB 库相同。
包含 tiny_obj_loader.h 文件,并确保在一个源文件中定义 TINYOBJLOADER_IMPLEMENTATION 以包含函数体并避免链接器错误:
#define TINYOBJLOADER_IMPLEMENTATION
#include <tiny_obj_loader.h>我们现在将编写一个 loadModel 函数,使用这个库来填充 vertices 和 indices 容器,其中包含来自网格的顶点数据。
它应该在创建顶点和索引缓冲区之前的某个地方调用:
void initVulkan() {
...
loadModel();
createVertexBuffer();
createIndexBuffer();
...
}
...
void loadModel() {
}通过调用 tinyobj::LoadObj 函数将模型加载到库的数据结构中:
void loadModel() {
tinyobj::attrib_t attrib;
std::vector<tinyobj::shape_t> shapes;
std::vector<tinyobj::material_t> materials;
std::string warn, err;
if (!tinyobj::LoadObj(&attrib, &shapes, &materials, &warn, &err, MODEL_PATH.c_str())) {
throw std::runtime_error(warn + err);
}
}OBJ 文件由位置、法线、纹理坐标和面组成。 面由任意数量的顶点组成,每个顶点通过索引引用位置、法线和/或纹理坐标。 这使得不仅可以重用整个顶点,还可以重用单个属性。
attrib 容器在其 attrib.vertices、attrib.normals 和 attrib.texcoords 向量中保存所有的位置、法线和纹理坐标。
shapes 容器包含所有单独的对象及其面。
每个面由一个顶点数组组成,每个顶点包含位置、法线和纹理坐标属性的索引。
OBJ 模型还可以为每个面定义材质和纹理,但我们将忽略这些。
err 字符串包含加载文件时发生的错误,warn 字符串包含警告,比如缺少材质定义。
只有当 LoadObj 函数返回 false 时,加载才真正失败。
如上所述,OBJ 文件中的面实际上可以包含任意数量的顶点,而我们的应用程序只能渲染三角形。
幸运的是,LoadObj 有一个可选参数,可以自动将这些面三角化,默认情况下是启用的。
我们将把文件中的所有面合并到一个模型中,所以只需遍历所有的形状:
for (const auto& shape : shapes) {
}三角化功能已经确保每个面有三个顶点,所以我们现在可以直接遍历顶点并将它们直接转储到我们的 vertices 向量中:
for (const auto& shape : shapes) {
for (const auto& index : shape.mesh.indices) {
Vertex vertex{};
vertices.push_back(vertex);
indices.push_back(indices.size());
}
}为了简单起见,我们现在假设每个顶点都是唯一的,因此使用简单的自增索引。
index 变量的类型是 tinyobj::index_t,它包含 vertex_index、normal_index 和 texcoord_index 成员。
我们需要使用这些索引在 attrib 数组中查找实际的顶点属性:
vertex.pos = {
attrib.vertices[3 * index.vertex_index + 0],
attrib.vertices[3 * index.vertex_index + 1],
attrib.vertices[3 * index.vertex_index + 2]
};
vertex.texCoord = {
attrib.texcoords[2 * index.texcoord_index + 0],
attrib.texcoords[2 * index.texcoord_index + 1]
};
vertex.color = {1.0f, 1.0f, 1.0f};不幸的是,attrib.vertices 数组是一个 float 值数组,而不是类似 glm::vec3 的东西,所以您需要将索引乘以 3。
同样,每个条目有两个纹理坐标分量。
偏移量 0、1 和 2 用于访问 X、Y 和 Z 分量,或者在纹理坐标的情况下是 U 和 V 分量。
现在启用优化运行您的程序(例如,Visual Studio 中的 Release 模式和 GCC 的 -O3 编译器标志)。
这是必要的,因为否则加载模型将非常慢。
您应该看到类似以下内容:
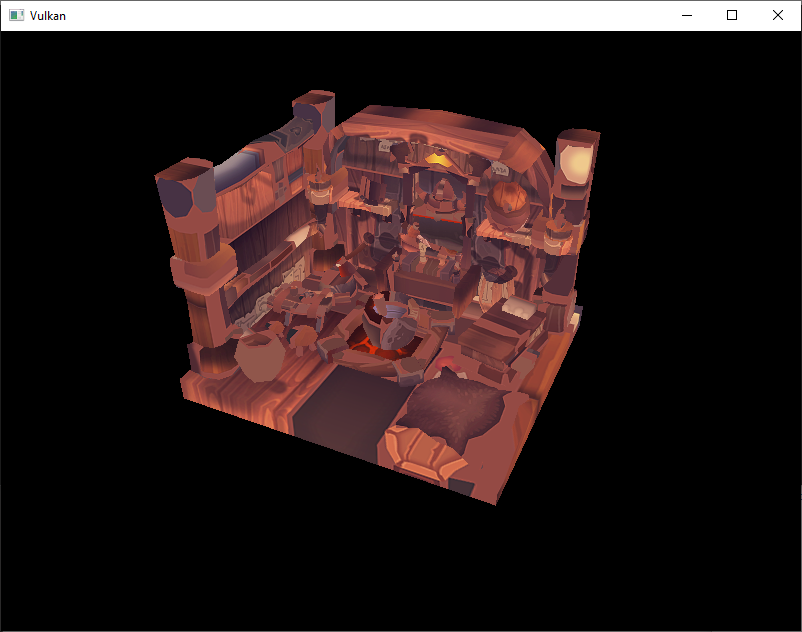
很好,几何体看起来正确,但纹理怎么了?
OBJ 格式假设一个坐标系统,其中垂直坐标 0 表示图像的底部,但是我们已经以从上到下的方向将图像上传到 Vulkan 中,其中 0 表示图像的顶部。
通过翻转纹理坐标的垂直分量来解决这个问题:
vertex.texCoord = {
attrib.texcoords[2 * index.texcoord_index + 0],
1.0f - attrib.texcoords[2 * index.texcoord_index + 1]
};当您再次运行程序时,您现在应该看到正确的结果:
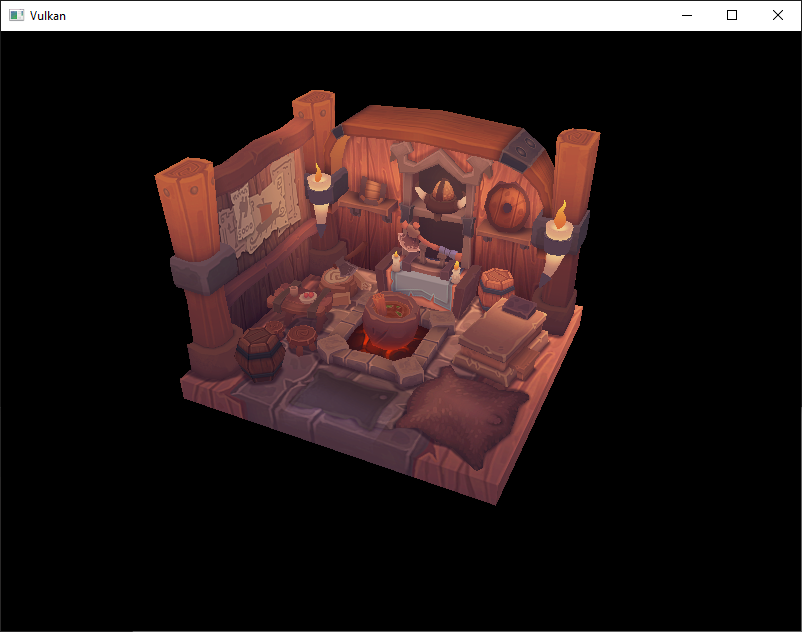
所有这些辛勤工作终于开始通过这样的演示得到回报!
当模型旋转时,您可能会注意到后部(墙壁的背面)看起来有点奇怪。 这是正常的,只是因为模型实际上并不是设计用来从那一侧观看的。
顶点去重
不幸的是,我们还没有真正利用索引缓冲区。
vertices 向量包含大量重复的顶点数据,因为许多顶点包含在多个三角形中。
我们应该只保留唯一的顶点,并在它们出现时使用索引缓冲区重用它们。
实现这一点的一个直接方法是使用 map 或 unordered_map 来跟踪唯一的顶点和各自的索引:
#include <unordered_map>
...
std::unordered_map<Vertex, uint32_t> uniqueVertices{};
for (const auto& shape : shapes) {
for (const auto& index : shape.mesh.indices) {
Vertex vertex{};
...
if (uniqueVertices.count(vertex) == 0) {
uniqueVertices[vertex] = static_cast<uint32_t>(vertices.size());
vertices.push_back(vertex);
}
indices.push_back(uniqueVertices[vertex]);
}
}每次我们从 OBJ 文件中读取一个顶点时,我们检查是否已经看到过一个具有完全相同位置和纹理坐标的顶点。
如果没有,我们将它添加到 vertices 中,并将其索引存储在 uniqueVertices 容器中。
之后,我们将新顶点的索引添加到 indices 中。
如果我们之前已经看到过完全相同的顶点,那么我们在 uniqueVertices 中查找它的索引,并将该索引存储在 indices 中。
程序现在将无法编译,因为在哈希表中使用我们的 Vertex 结构体这样的用户定义类型作为键需要我们实现两个函数:相等性测试和哈希计算。
前者可以通过在 Vertex 结构体中重写 == 运算符来轻松实现:
bool operator==(const Vertex& other) const {
return pos == other.pos && color == other.color && texCoord == other.texCoord;
}Vertex 的哈希函数是通过为 std::hash<T> 指定模板特化来实现的。
哈希函数是一个复杂的主题,但 cppreference.com 推荐 以下方法,将结构体的字段组合起来创建一个质量不错的哈希函数:
namespace std {
template<> struct hash<Vertex> {
size_t operator()(Vertex const& vertex) const {
return ((hash<glm::vec3>()(vertex.pos) ^
(hash<glm::vec3>()(vertex.color) << 1)) >> 1) ^
(hash<glm::vec2>()(vertex.texCoord) << 1);
}
};
}这段代码应该放在 Vertex 结构体之外。
GLM 类型的哈希函数需要使用以下头文件包含:
#define GLM_ENABLE_EXPERIMENTAL
#include <glm/gtx/hash.hpp>哈希函数定义在 gtx 文件夹中,这意味着它在技术上仍然是 GLM 的实验性扩展。
因此,您需要定义 GLM_ENABLE_EXPERIMENTAL 来使用它。
这意味着 API 可能会随着 GLM 的新版本而改变,但实际上 API 非常稳定。
您现在应该能够成功编译和运行您的程序了。
如果您检查 vertices 的大小,那么您会看到它已经从 1,500,000 缩小到 265,645!
这意味着每个顶点平均在约 6 个三角形中被重用。
这确实为我们节省了大量的 GPU 内存。
在 下一章 中,我们将学习一种改进纹理渲染的技术。
C++ 代码 / slang 着色器 / GLSL 顶点着色器 / GLSL 片段着色器