第 5 章 深度学习 (Deep Learning)
核心结论
-
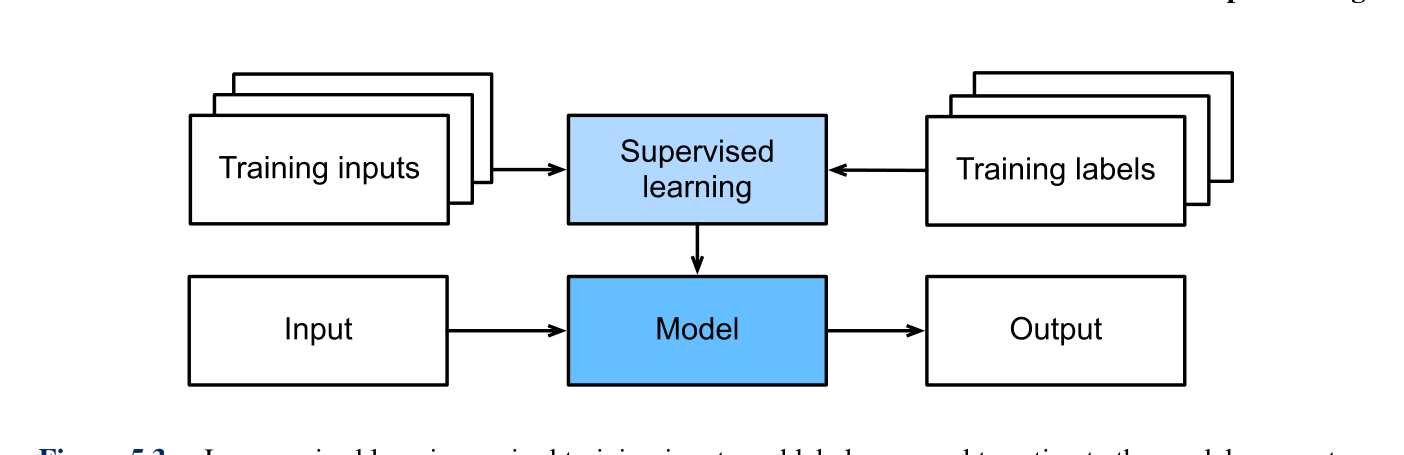
监督学习(§5.1):给定 (x, y) 训练对,学习映射
f: X → Y;KNN / SVM / 决策树 / 神经网络。 -
无监督学习(§5.2):只有 x 无标签;聚类(K-means)、降维(PCA / t-SNE)、自监督(旋转预测 / 拼图)。
-
深度神经网络 (DNN)(§5.3):多层感知机(MLP);激活函数(ReLU / Sigmoid / Tanh);反向传播;BatchNorm / Dropout / 残差连接。
-
卷积神经网络 (CNN)(§5.4):AlexNet / VGG / ResNet / MobileNet;卷积 + 池化 + 全连接;ImageNet 预训练 + 迁移学习。
-
复杂模型(§5.5):RNN / LSTM / Transformer / ViT / Swin / Diffusion;时序 / 注意力 / 生成。
|
本章主旨
本章是 CV 的"深度学习章"——理解 CNN / ResNet / ViT 等现代架构。深度学习 2012 年起主导 CV,本章给出完整的理论与实践工具。后续章节(识别 / 检测 / 分割 / 重建)几乎全部基于本章的深度学习。 |
一、核心概念
本章围绕 6 个核心概念展开:监督学习 → 无监督学习 → DNN → CNN → 复杂模型(Transformer / Diffusion)。
| 概念 | 定义 + 重要性 | 实现提示 |
|---|---|---|
监督学习 |
给定 (x, y) 学习 |
§5.1;CV 中分类 / 检测 / 分割都用监督学习。 |
无监督学习 |
只有 x 无标签;聚类 / 降维 / 自监督。 |
§5.2;自监督学习是基础模型的关键。 |
深度神经网络 (DNN) |
MLP + 激活函数 + 反向传播;BatchNorm / Dropout / 残差。 |
§5.3;现代 CV 的基础架构。 |
卷积神经网络 (CNN) |
AlexNet / VGG / ResNet / MobileNet;ImageNet 预训练。 |
§5.4;CV 任务的事实标准。 |
复杂模型 |
RNN / LSTM / Transformer / ViT / Swin / Diffusion。 |
§5.5;时序 / 注意力 / 生成。 |
训练技巧 |
SGD / Adam / 学习率调度 / 数据增强 / 迁移学习 / 预训练 + 微调。 |
§5.4-§5.5;现代 CV 必备工具。 |
二、详细笔记
2.1 监督学习 (Supervised Learning)
What:给定 (x, y) 训练对,学习映射 f: X → Y;最小化损失 L(f(x), y)。
Why:CV 中分类 / 检测 / 分割 / 关键点检测都用监督学习。
How:
监督学习算法(§5.1):
-
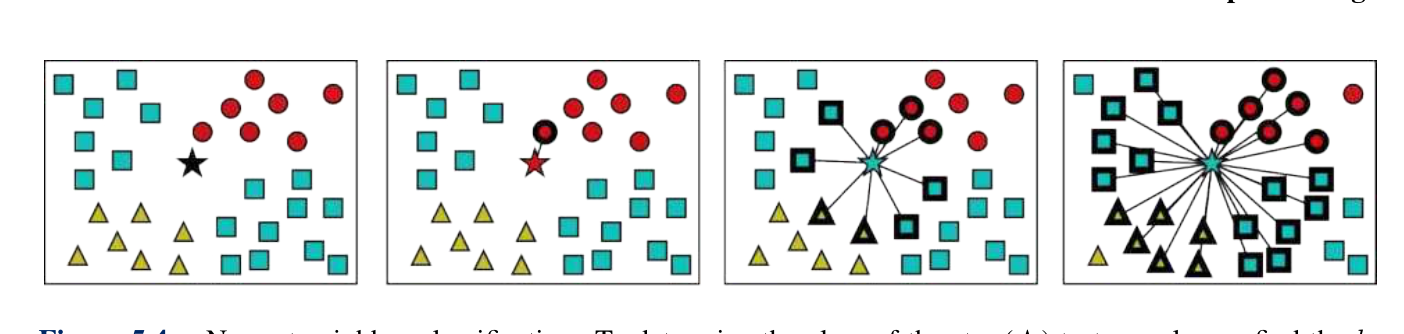
KNN(K-近邻):简单但慢;无训练过程。
-
SVM(支持向量机):最大化间隔;核函数可扩展到非线性。
-
决策树 / 随机森林:可解释;特征重要度。
-
神经网络:通用逼近器;需大量数据。
损失函数:
-
分类:交叉熵
L = -\sum y_i \log \hat{y}_i。 -
回归:MSE
L = \sum (y_i - \hat{y}_i)²。
|
监督学习的工程权衡
|
When:分类 / 检测 / 分割 / 关键点;表格数据用 RF / SVM。
Example:sklearn.svm.SVC;sklearn.ensemble.RandomForestClassifier;PyTorch 自定义 NN。
2.2 无监督学习 (Unsupervised Learning)
What:只有 x 无标签;学习数据分布 / 聚类 / 降维。
Why:标注数据昂贵;无监督学习挖掘未标注数据;自监督是基础模型的关键。
How:
无监督学习方法(§5.2):
-
聚类:K-means / DBSCAN / 谱聚类。
-
降维:PCA / t-SNE / UMAP。
-
密度估计:GMM / KDE。
-
自监督:旋转预测 / 拼图 / 对比学习(SimCLR / MoCo)。
|
自监督学习的崛起
|
When:聚类(图像分组);降维(可视化);自监督预训练。
Example:sklearn.cluster.KMeans;sklearn.decomposition.PCA;timm 库提供 MoCo / DINO 预训练模型。
2.3 深度神经网络 (DNN)
What:多层感知机(MLP)+ 激活函数 + 反向传播;现代 CV 的基础。
Why:通用逼近器(理论上可拟合任意函数);深度 = 表达力。
How:
MLP 结构(§5.3):
-
W^{(l)}:第 l 层权重矩阵。 -
σ:激活函数(ReLU / Sigmoid / Tanh)。 -
反向传播:链式法则求梯度。
关键组件:
-
激活函数:ReLU(最常用)/ Sigmoid / Tanh / GELU / Swish。
-
BatchNorm:归一化每层输入;加速收敛。
-
Dropout:训练时随机丢弃部分神经元;正则化。
-
残差连接:
y = F(x) + x;解决梯度消失;ResNet 核心。
|
深度学习的工程经验
|
When:所有 CV 任务;时间序列;NLP;多模态。
Example:nn.Linear(in, out) + nn.ReLU() + nn.BatchNorm1d(out);PyTorch nn.Sequential 快速堆叠。
2.4 卷积神经网络 (CNN)
What:用卷积层替代全连接;专为图像设计;ImageNet 2012 起主导 CV。
Why:权值共享 + 局部连接 = 参数量少 + 平移不变性;现代 CV 事实标准。
How:
CNN 核心组件(§5.4):
-
卷积层:与 §3.2 线性滤波相同,但权重可学习。
-
池化层:最大池化 / 平均池化;降低分辨率。
-
激活函数:ReLU(最常用)。
-
全连接层:最后几层用于分类。
经典架构:
-
LeNet-5(1998):第一个 CNN。
-
AlexNet(2012):ImageNet 突破;ReLU + Dropout。
-
VGG(2014):3×3 卷积堆叠;简单有效。
-
ResNet(2015):残差连接;训练 100+ 层网络。
-
MobileNet(2017):深度可分离卷积;移动端。
-
EfficientNet(2019):复合缩放;最优精度 / 效率。
|
CNN 演进的"经验法则"
|
When:图像分类 / 检测 / 分割;预训练 backbone(迁移学习)。
Example:torchvision.models.resnet50(pretrained=True);timm.create_model('efficientnet_b0')。
2.5 Transformer 与注意力 (Transformer & Attention)
What:用注意力机制替代卷积 / 循环;NLP 革命后扩展到 CV(ViT / Swin)。
Why:长距离依赖 + 并行训练 + 统一 NLP / CV 框架;2021+ 主流架构。
How:
Transformer 核心(§5.5):
-
自注意力:
\text{Attn}(Q, K, V) = \text{softmax}(Q K^T / \sqrt{d}) V。 -
多头注意力:多个子空间并行。
-
位置编码:
PE(pos, 2i) = \sin(pos / 10000^{2i/d})。
视觉 Transformer:
-
ViT(2020):图像分 patch → 序列 → Transformer encoder。
-
Swin(2021):层级 + 滑动窗口注意力;目标检测 / 分割 SOTA。
-
DETR(2020):Transformer 端到端检测。
|
Transformer vs CNN 的工程取舍
|
When:大模型(CLIP / SAM / GPT-4V);检测 / 分割 SOTA;多模态。
Example:timm 提供 ViT / Swin / DETR;transformers 库 HuggingFace。
2.6 训练技巧 (Training Tricks)
What:学习率 / 数据增强 / 预训练 + 微调 / 分布式训练。
Why:训练好的 CV 模型 = 数据 + 架构 + 训练技巧三要素;技巧决定上限。
How:
训练技巧(§5.4-§5.5):
-
学习率:最关键的超参;用 warmup + cosine decay。
-
优化器:Adam(默认)/ SGD + momentum(大模型)。
-
数据增强:随机裁剪 / 翻转 / 颜色抖动 / Mixup / CutMix。
-
正则化:Dropout / Weight Decay / Label Smoothing。
-
迁移学习:ImageNet 预训练 + 小数据微调。
-
分布式训练:DDP / ZeRO / FSDP。
|
现代 CV 训练的"配方"
|
When:训练任何 CV 模型;微调预训练模型;多 GPU 训练。
Example:torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True);transformers.Trainer 自动分布式。
三、关键图表
视觉图表


四、思维导图
mindmap
root((第 5 章 深度学习))
监督学习
KNNSVM
决策树
神经网络
无监督学习
Kmeans
PCAtSNE
自监督对比
DNN
MLP
ReLU激活
BatchNormDropout
残差连接
CNN
AlexNet
VGGResNet
MobileNet
EfficientNet
Transformer
自注意力
ViT
SwinDETR
训练技巧
Adam
数据增强
预训练微调
分布式五、重点与易错点
-
CNN 仍是 CV 主流:尽管 ViT 兴起,CNN + Transformer 混合架构(Swin / ConvNeXt)更适合实际部署。
-
ResNet 是里程碑:残差连接让训练 100+ 层网络成为可能;后续所有架构借鉴。
-
自监督是基础模型的关键:CLIP / SAM / DINO 都靠自监督预训练;标注数据昂贵。
-
学习率是最关键超参:warmup + cosine schedule 是稳定默认。
-
数据增强 = 隐式正则化:Mixup / CutMix 比单纯 Dropout 更强。
-
ImageNet 预训练仍是有效起点:迁移学习到下游任务通常 +5-10% 精度。
-
大模型不等于好模型:模型大小应与数据 / 任务匹配;MobileNet 在移动端优。
-
Transformer 在 CV 的崛起:ViT 需大数据集;Swin 用层级窗口降低计算量。
-
跨章衔接:第 6 章识别用本章 CNN;第 7 章特征用本章预训练 backbone;第 11 章 SLAM 用本章 Transformer 做前端。